
GridSearchCV评分参数:使用评分=‘f1’或scoring=None (默认情况下使用精度)给出相同的结果
我使用的例子摘自书“掌握机器学习与科学工具包学习”。
它使用决策树来预测网页上的每个图像是广告还是文章内容。然后,可以使用层叠样式表隐藏被归类为广告的图像。这些数据可以从互联网广告数据集:http://archive.ics.uci.edu/ml/datasets/Internet+Advertisements公开获得,其中包含了3279幅图像的数据。
以下是完成分类任务的完整代码:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
import sys,random
def main(argv):
df = pd.read_csv('ad-dataset/ad.data', header=None)
explanatory_variable_columns = set(df.columns.values)
response_variable_column = df[len(df.columns.values)-1]
explanatory_variable_columns.remove(len(df.columns.values)-1)
y = [1 if e == 'ad.' else 0 for e in response_variable_column]
X = df[list(explanatory_variable_columns)]
X.replace(to_replace=' *\?', value=-1, regex=True, inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y,random_state=100000)
pipeline = Pipeline([('clf',DecisionTreeClassifier(criterion='entropy',random_state=20000))])
parameters = {
'clf__max_depth': (150, 155, 160),
'clf__min_samples_split': (1, 2, 3),
'clf__min_samples_leaf': (1, 2, 3)
}
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1,verbose=1, scoring='f1')
grid_search.fit(X_train, y_train)
print 'Best score: %0.3f' % grid_search.best_score_
print 'Best parameters set:'
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print '\t%s: %r' % (param_name, best_parameters[param_name])
predictions = grid_search.predict(X_test)
print classification_report(y_test, predictions)
if __name__ == '__main__':
main(sys.argv[1:])在GridSearchCV中使用 scoring='f1' 的结果如下所示:
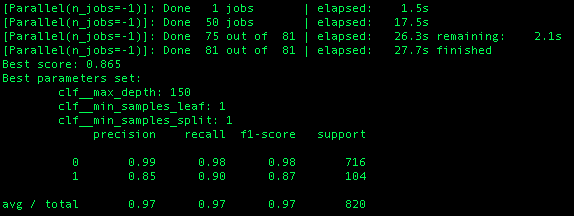
使用scoring=None (默认精度度量)的结果与使用F1评分:的结果相同
如果我没有错的话,用不同的评分函数来优化参数搜索会产生不同的结果。下面的例子表明,当使用打分=“精度”时,得到了不同的结果。
scoring='precision' 应用的结果与其他两例不同。“召回”等也是如此:
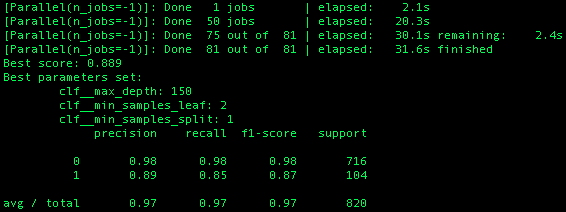
为什么'F1‘和’None‘,默认的准确性,给出相同的结果??
编辑
我同意法比安和塞巴斯蒂安的两个答案。问题应该是小的param_grid。但我只想澄清一下,当我使用完全不同的数据集100:1 (这应该会影响准确性)和使用Logistic回归时,问题会激增(而不是这里的例子中的问题)。在这种情况下,“F1”和“精确度”也给出了同样的结果。
在本例中,我使用的param_grid如下:
parameters = {"penalty": ("l1", "l2"),
"C": (0.001, 0.01, 0.1, 1, 10, 100),
"solver": ("newton-cg", "lbfgs", "liblinear"),
"class_weight":[{0:4}],
}我想参数选择也太小了。
回答 3
Stack Overflow用户
发布于 2015-10-01 20:54:36
我认为作者并没有很好地选择这个例子。我在这里可能遗漏了一些东西,但min_samples_split=1对我来说没有意义:这不等于设置min_samples_split=2,因为您不能拆分一个示例--本质上,这是浪费计算时间。
文档:
min_samples_split:“拆分内部节点所需的最小样本数。”
顺便说一句。这是一个非常小的网格,没有太多的选择,这可能解释了为什么accuracy和f1为您提供相同的参数组合,从而给出相同的计分表。
正如上面提到的,数据集可能是很好的平衡,这就是为什么F1和精度分数可能倾向于相同的参数组合。因此,使用(a) GridSearch评分和(b)精度进一步查看您的F1结果,我得出的结论是,在这两种情况下,150个深度是最好的。由于这是较低的边界,它给了您一个轻微的后置,较低的“深度”值可能会更好地工作。但是,我怀疑树在这个数据集中甚至没有那么深(在达到最大深度之前,您甚至可以得到“纯”叶子)。
所以,让我们使用下面的参数网格,用一些更合理的值来重复这个实验
parameters = {
'clf__max_depth': list(range(2, 30)),
'clf__min_samples_split': (2,),
'clf__min_samples_leaf': (1,)
}最佳F1评分的最佳“深度”似乎在15左右。
Best score: 0.878
Best parameters set:
clf__max_depth: 15
clf__min_samples_leaf: 1
clf__min_samples_split: 2
precision recall f1-score support
0 0.98 0.99 0.99 716
1 0.92 0.89 0.91 104
avg / total 0.98 0.98 0.98 820接下来,让我们尝试使用“准确性”(或None)作为我们的评分标准:
> Best score: 0.967
Best parameters set:
clf__max_depth: 6
clf__min_samples_leaf: 1
clf__min_samples_split: 2
precision recall f1-score support
0 0.98 0.99 0.98 716
1 0.93 0.85 0.88 104
avg / total 0.97 0.97 0.97 820正如你所看到的,你现在得到了不同的结果,如果你使用“精确”的话,“最佳”深度是不同的。
Stack Overflow用户
发布于 2015-10-01 16:06:41
我不同意用不同的评分函数优化参数搜索必然会产生不同的结果。如果您的数据集是平衡的(每个类中的样本数量大致相同),我希望模型选择的准确性和F1会产生非常相似的结果。
另外,请记住,GridSearchCV在离散网格上进行优化。也许使用一个更薄的参数网格会产生您正在寻找的结果。
Stack Overflow用户
发布于 2015-12-22 23:06:55
在不平衡数据集上,使用f1_score记分器的“标签”参数只使用您感兴趣的类的f1分数。或者考虑使用"sample_weight“。
https://stackoverflow.com/questions/32889929
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号