
R插入符号不一致导致模型调优
R插入符号不一致导致模型调优
提问于 2015-09-20 17:29:09
今天,使用插入符号包进行模型优化时,我遇到了这种奇怪的行为:给定调优参数T*的特定组合,如果单独计算T*或作为可能组合的网格的一部分,则与T*更改相关的度量(即Cohen's K)值。在下面的实例中,使用插入符号与gbm包进行接口。
# Load libraries and data
library (caret)
data<-read.csv("mydata.csv")
data$target<-as.factor(data$target)
# data are available at https://www.dropbox.com/s/1bglmqd14g840j1/mydata.csv?dl=0Pocedure 1: T*单独评估
#Define 5-fold cv as validation settings
fitControl <- trainControl(method = "cv",number = 5)
# Define the combination of tuning parameter for this example T*
gbmGrid <- expand.grid(.interaction.depth = 1,
.n.trees = 1000,
.shrinkage = 0.1, .n.minobsinnode=1)
# Fit a gbm with T* as model parameters and K as scoring metric.
set.seed(825)
gbmFit1 <- train(target ~ ., data = data,
method = "gbm",
distribution="adaboost",
trControl = fitControl,
tuneGrid=gbmGrid,
verbose=F,
metric="Kappa")
# The results show that T* is associated with Kappa = 0.47. Remember this result and the confusion matrix.
testPred<-predict(gbmFit1, newdata = data)
confusionMatrix(testPred, data$target)
# output selection
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 832 34
1 0 16
Kappa : 0.4703过程2: T*与其他调优配置文件一起评估
这里的所有内容都与过程1中的情况相同,除了考虑了几种调优参数{T}的组合之外:
# Notice that the original T* is included in {T}!!
gbmGrid2 <- expand.grid(.interaction.depth = 1,
.n.trees = seq(100,1000,by=100),
.shrinkage = 0.1, .n.minobsinnode=1)
# Fit the gbm
set.seed(825)
gbmFit2 <- train(target ~ ., data = data,
method = "gbm",
distribution="adaboost",
trControl = fitControl,
tuneGrid=gbmGrid2,
verbose=F,
metric="Kappa")
# Caret should pick the model with the highest Kappa.
# Since T* is in {T} I would expect the best model to have K >= 0.47
testPred<-predict(gbmFit2, newdata = data)
confusionMatrix(testPred, data$target)
# output selection
Reference
Prediction 0 1
0 831 47
1 1 3
Kappa : 0.1036 结果与我的预期不一致:{T}分数K=0.10中的最佳模型。如果T*有K= 0.47,并且它包含在{T}中,那怎么可能?另外,根据下面的图,步骤2中评估的T*的K值现在约为0.01。知道这是怎么回事吗?我是不是遗漏了什么?
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-09-20 21:42:55
我正在从您的数据和代码中获得一致的重采样结果。
第一个模型有Kappa = 0.00943
gbmFit1$results
interaction.depth n.trees shrinkage n.minobsinnode Accuracy Kappa AccuracySD
1 1 1000 0.1 1 0.9331022 0.009430576 0.004819004
KappaSD
1 0.0589132第二个模型对于n.trees = 1000具有相同的结果。
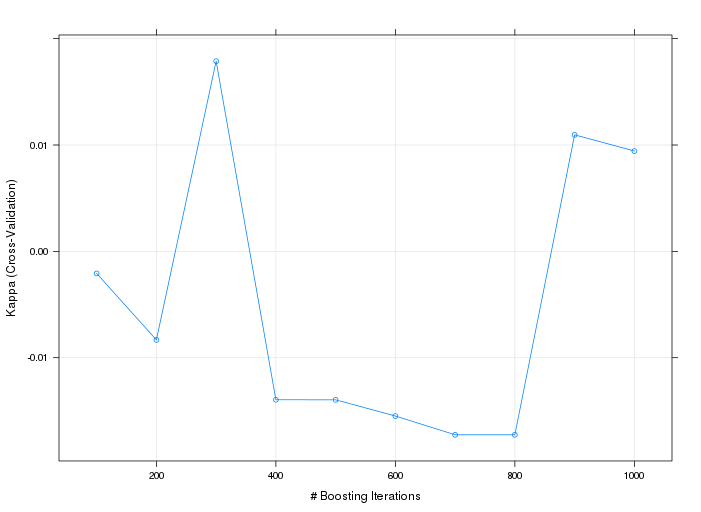
gbmFit2$results
shrinkage interaction.depth n.minobsinnode n.trees Accuracy Kappa AccuracySD
1 0.1 1 1 100 0.9421803 -0.002075765 0.002422952
2 0.1 1 1 200 0.9387776 -0.008326896 0.002468351
3 0.1 1 1 300 0.9365049 -0.012187900 0.002625886
4 0.1 1 1 400 0.9353749 -0.013950906 0.003077431
5 0.1 1 1 500 0.9353685 -0.013961221 0.003244201
6 0.1 1 1 600 0.9342322 -0.015486214 0.005202656
7 0.1 1 1 700 0.9319658 -0.018574633 0.007033402
8 0.1 1 1 800 0.9319658 -0.018574633 0.007033402
9 0.1 1 1 900 0.9342386 0.010955568 0.003144850
10 0.1 1 1 1000 0.9331022 0.009430576 0.004819004
KappaSD
1 0.004641553
2 0.004654972
3 0.003978702
4 0.004837097
5 0.004878259
6 0.007469843
7 0.009470466
8 0.009470466
9 0.057825336
10 0.058913202请注意,第二次运行中最好的模型是n.trees = 900。
gbmFit2$bestTune
n.trees interaction.depth shrinkage n.minobsinnode
9 900 1 0.1 1由于train根据您的度量选择“最佳”模型,您的第二个预测是使用不同的模型(n.trees为900而不是1000)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/32682259
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号