
ggplot2创建时频
ggplot2创建时频
提问于 2015-09-12 02:43:23
我很难根据我的数据创建ggplot2。我需要创建一个情节如下所示:
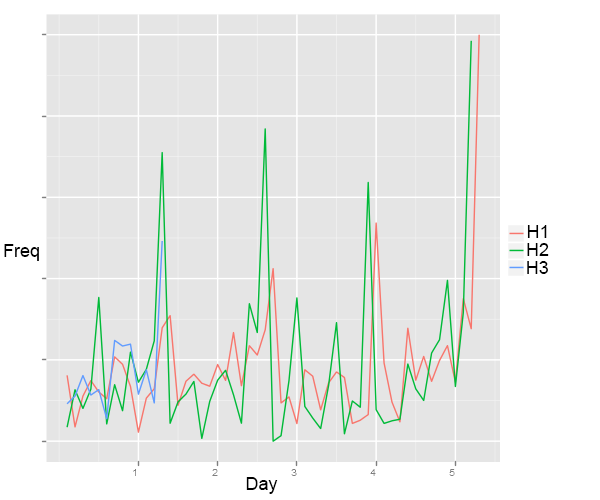
如果你能给我一些建议,这对我的研究真的很有好处。感谢您的时间和努力,提前。
一个非常小的数据集(df)示例如下所示:
tweet_created_at hashtag_text
2015-05-08 00:07:58 ogretmenemayistamujdehazirandaatama
2015-05-08 00:07:58 onlarkonusurakpartiyapar
2015-05-08 00:10:48 ogretmenemayistamujdehazirandaatama
2015-05-08 00:10:48 onlarkonusurakpartiyapar
2015-05-08 02:50:03 onlarkonusurakpartiyapar
2015-05-08 00:10:56 ogretmenemayistamujdehazirandaatama
2015-05-08 00:10:56 onlarkonusurakpartiyapar
2015-05-08 02:53:13 onlarkonusurakpartiyapar
2015-05-08 02:53:13 pinokyokemal
2015-05-08 00:11:03 ogretmenemayistamujdehazirandaatama
2015-05-08 00:11:03 onlarkonusurakpartiyapar
2015-05-08 00:11:06 ogretmenemayistamujdehazirandaatama
2015-05-08 00:11:06 onlarkonusurakpartiyapar
2015-05-08 02:53:48 bingolunkararibuyumenindevami
2015-05-08 02:53:48 onlarkonusurakpartiyapar
2015-05-08 00:11:17 ogretmenemayistamujdehazirandaatama
2015-05-08 00:11:17 onlarkonusurakpartiyapar
2015-05-08 00:16:21 ogretmenemayistamujdehazirandaatama
2015-05-08 00:16:21 onlarkonusurakpartiyapar我使用了这个脚本,但我不知道如何创建频率部分:
ggplot(data=df,
aes(x=as.POSIXct(tweet_created_at), y=hashtag_text,color=hashtag_text)) +
geom_line()我知道y轴的值是不正确的,但是我没有找到正确的版本。它创建了这样的东西:
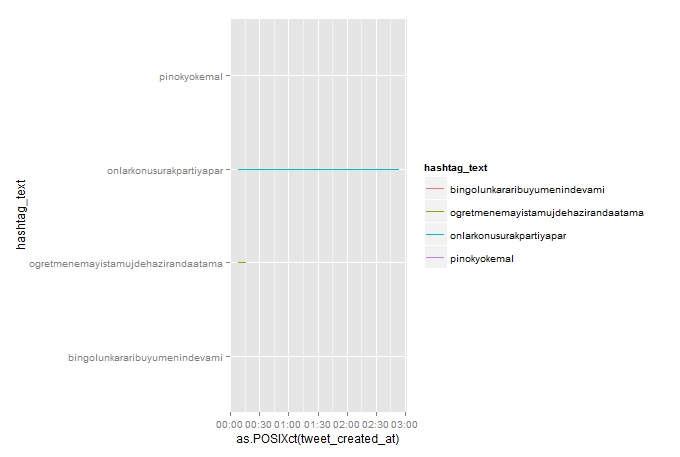
PS:我的数据集中有数百个哈希标签,所以我需要选择前25个标签。
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-09-13 12:45:27
您可以使用geom_freqpoly。如果您的tweet_created_at变量还不是POSIXct,那么转换它:
df$tweet_created_at <- as.POSIXct(df$tweet_created_at )然后找到最常见的哈希标签并创建一个select变量:
#will look for top 2 now, easily expanded to 25
hashtag_table <- sort(table(df$hashtag_text),decreasing=T)
df$select <- as.character(df$hashtag_text) %in% names(hashtag_table)[1:2]然后情节:
p1 <- ggplot(df[df$select,],
aes(x=tweet_created_at,group=hashtag_text, colour=hashtag_text)) +
geom_freqpoly(binwidth=30*60) #as POSIXct, bindwidth in seconds. Now 30 min结果(有面,因为重叠的数据)
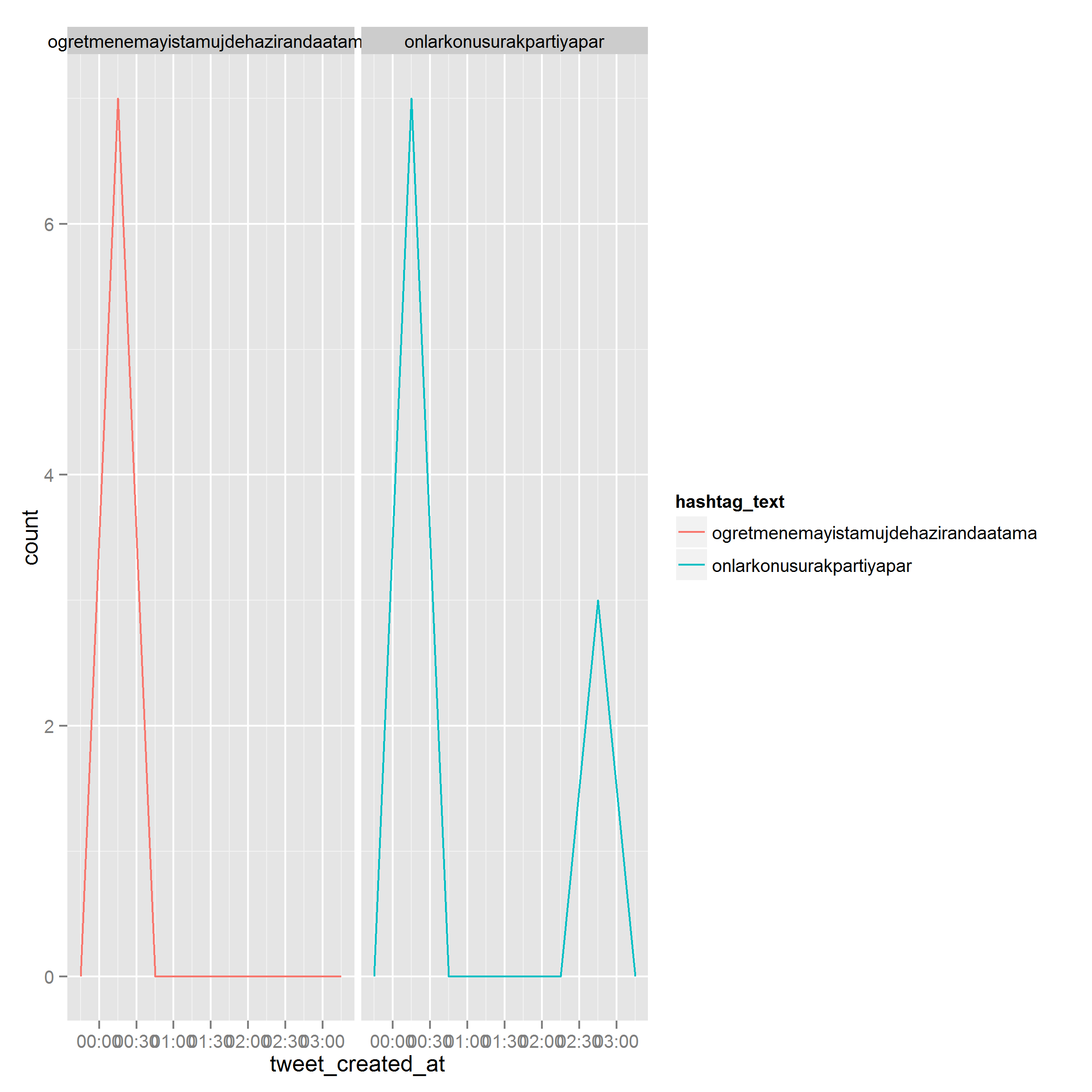
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/32534643
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号