
使用Tesseract-OCR进行图像到文本的识别比使用我的Python代码手工预处理图像更好
使用Tesseract-OCR进行图像到文本的识别比使用我的Python代码手工预处理图像更好
提问于 2015-09-09 07:13:10
我试图用Python编写代码,用于使用Tesseract-OCR进行手动图像预处理和识别。
手册过程:
为了手动识别单个图像的文本,我使用Gimp对图像进行预处理,并创建一个TIF图像。然后我把它喂给Tesseract-OCR,它正确地识别了它。
用Gimp对图像进行预处理-
- 将模式更改为RGB /灰度 菜单--图像--模式- RGB
- 脱粒 菜单--工具--彩色工具--阈值--自动
- 将模式更改为索引 菜单--图像--模式-索引
- 调整大小/比例至宽度>300 to 菜单--图像--缩放图像-- Width=300
- 保存为Tif
然后我给它喂食-
$ tesseract captcha.tif output -psm 6我一直都能得到准确的结果。
Python代码:
我试过用OpenCV和Tesseract复制上述程序-
def binarize_image_using_opencv(captcha_path, binary_image_path='input-black-n-white.jpg'):
im_gray = cv2.imread(captcha_path, cv2.CV_LOAD_IMAGE_GRAYSCALE)
(thresh, im_bw) = cv2.threshold(im_gray, 128, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# although thresh is used below, gonna pick something suitable
im_bw = cv2.threshold(im_gray, thresh, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite(binary_image_path, im_bw)
return binary_image_path
def preprocess_image_using_opencv(captcha_path):
bin_image_path = binarize_image_using_opencv(captcha_path)
im_bin = Image.open(bin_image_path)
basewidth = 300 # in pixels
wpercent = (basewidth/float(im_bin.size[0]))
hsize = int((float(im_bin.size[1])*float(wpercent)))
big = im_bin.resize((basewidth, hsize), Image.NEAREST)
# tesseract-ocr only works with TIF so save the bigger image in that format
tif_file = "input-NEAREST.tif"
big.save(tif_file)
return tif_file
def get_captcha_text_from_captcha_image(captcha_path):
# Preprocess the image befor OCR
tif_file = preprocess_image_using_opencv(captcha_path)
# Perform OCR using tesseract-ocr library
# OCR : Optical Character Recognition
image = Image.open(tif_file)
ocr_text = image_to_string(image, config="-psm 6")
alphanumeric_text = ''.join(e for e in ocr_text)
return alphanumeric_text 但我没有得到同样的准确性。我错过了什么?
更新1:
- 原始图像

- 使用Gimp创建的Tif图像
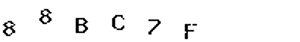
- 由我的python代码创建的Tif图像
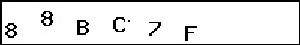
更新2:
此代码可在https://github.com/hussaintamboli/python-image-to-text上使用。
回答 1
Stack Overflow用户
发布于 2016-10-26 17:01:11
如果输出与预期输出的偏差最小(如注释中所建议的“额外的”、“等等),请尝试将字符识别限制在您期望的字符集上(例如字母数字)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/32473095
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号