
我可以在C源代码级别分析OpenACC内核吗?
我正试图用openacc和PGI 15.7编译器加速我的代码.
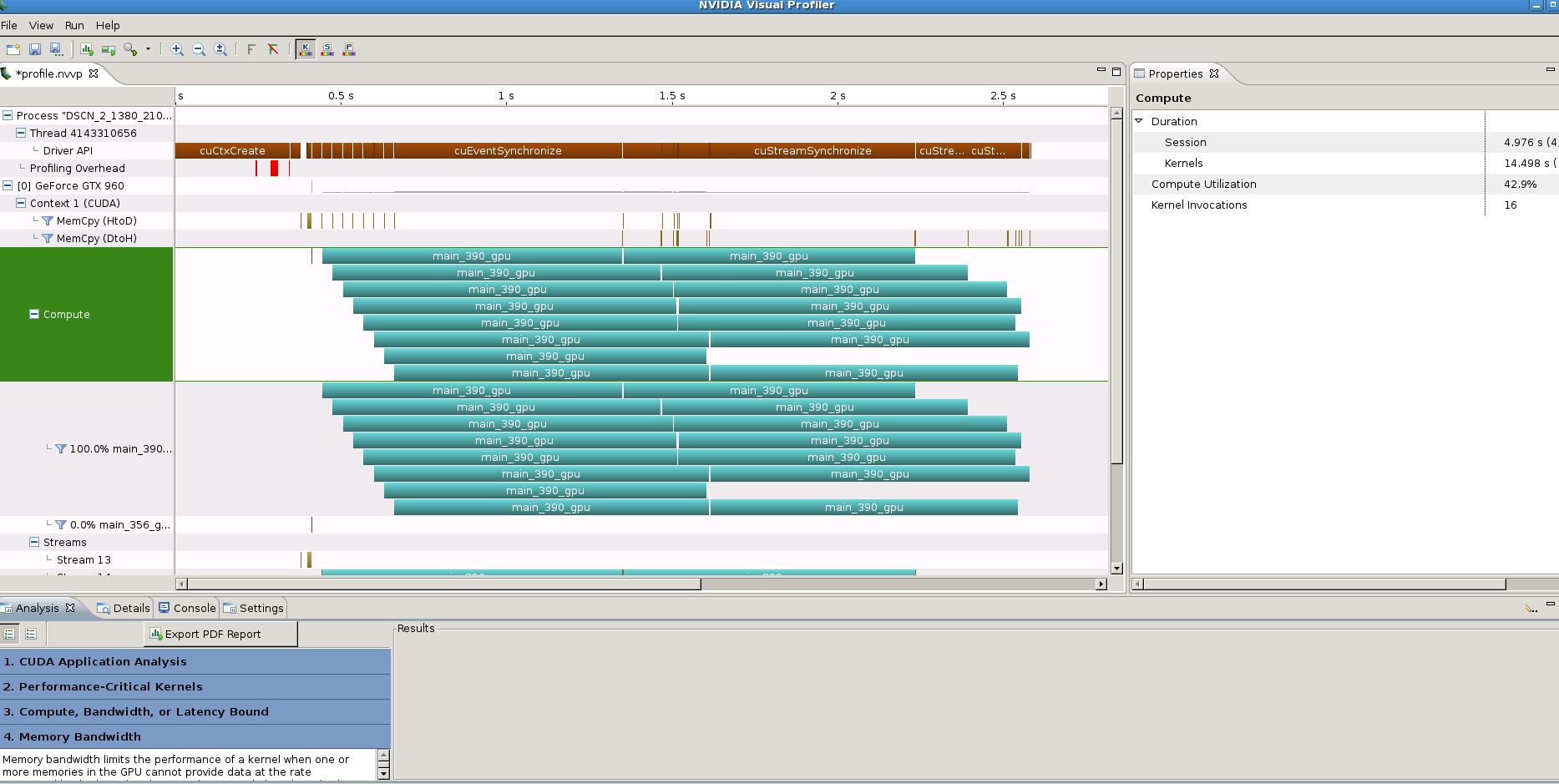
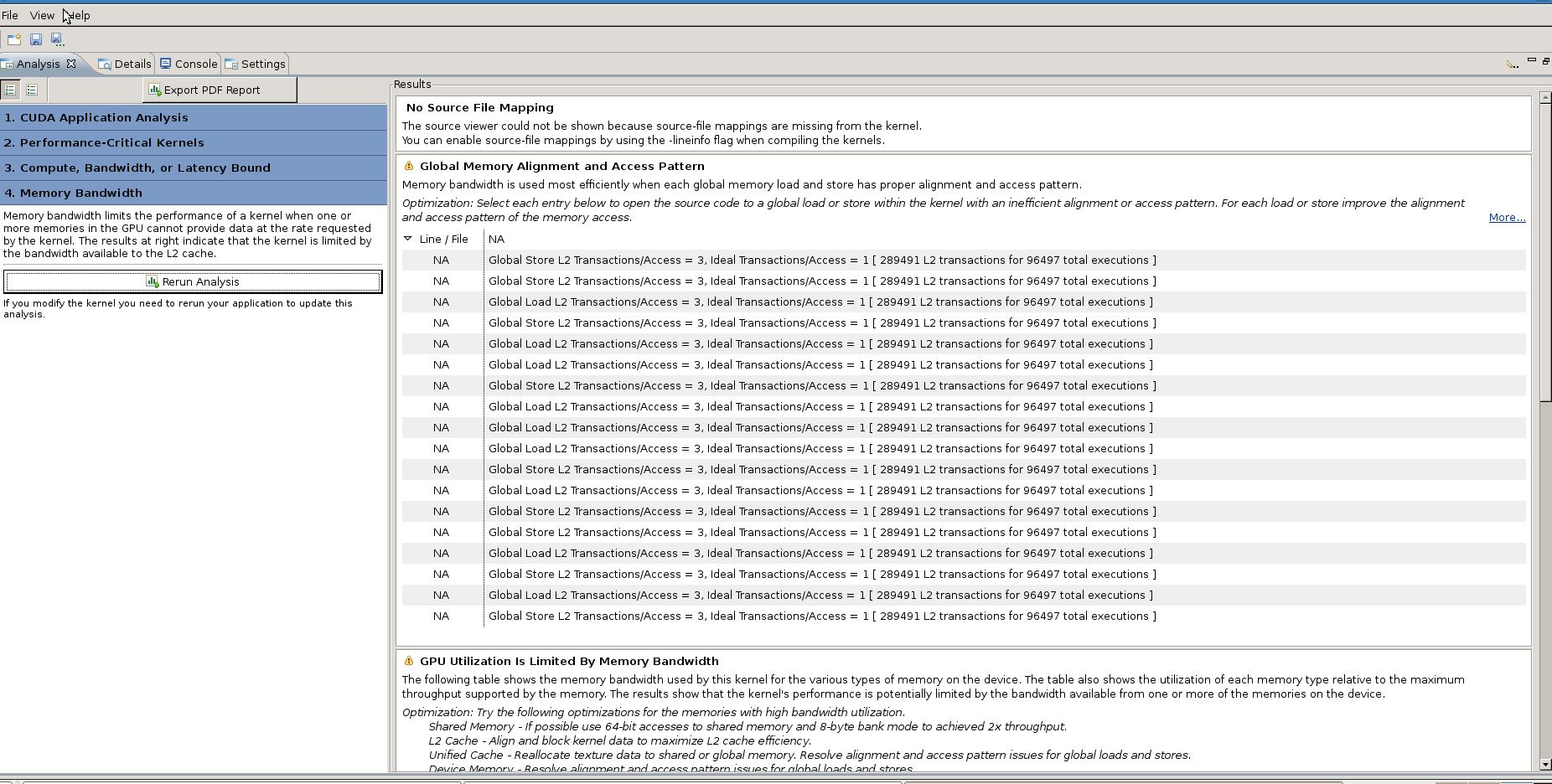
我想在C源代码级别分析我的代码。当我运行nvvp时,我使用的是CUDA 7.0中的'nvvp‘分析器,我可以使用’分析点击‘,并且可以得到哪个延迟是我的代码慢下来的原因。(数据依赖、条件分支和带宽.等)
但是,我无法得到基于行的分析,而只能进行“内核”级别分析。(例如,main_300_gpu内核使用10s)。所以我很难知道我要在哪里修改代码。
有没有办法在源代码级中分析我的代码?
我在用
PGI 15.7 (使用pgcc)
CUDA 7.0
NVIDIA GTX 960
Ubuntu14.04 LTS x86_64
我的nvvp报告截图
回答 2
Stack Overflow用户
发布于 2015-09-14 21:56:01
您还可以尝试添加标志"-ta=tesla:lineinfo“,让编译器为分析器添加源代码关联(它与nvcc的标志相同)。尽管正如Bob所指出的,代码可能已被大量转换,因此行信息许多并不直接与原始源对应。
Stack Overflow用户
发布于 2015-09-09 02:15:43
在当前时间(以及在CUDA 7.5或更高版本,有一个cc5.2或更高的GPU),nvvp分析器能联想到各种采样执行活动与CUDA C/C++的源代码行。
但是,目前,这种功能并没有扩展到OpenACC C/C++ (或Fortran)源代码行。
但是,仍然可以将活动与反汇编相关联,并且可能与PGI无选择生成的中间C源文件相关联。然而,这些代码中的Niether与OpenACC源代码有很大的相似之处。
使用PGI工具分析OpenACC代码的另一个选项是在执行代码之前设置PGI_ACC_TIME=1环境变量。这将使内置在运行库中的轻量级分析器能够分析OpenACC代码的执行特性,特别是那些与加速器区域相关的部分。对输出进行注释,以便您可以参考源代码中的行。
https://stackoverflow.com/questions/32454143
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号