
将Pandas pivot_table与margins=True一起使用时出错
将Pandas pivot_table与margins=True一起使用时出错
提问于 2015-09-04 14:15:34
我的代码(来自Python数据科学手册 (O‘’Reilly)一书):
完全披露:在撰写本书的时候,这本书还处于早期发行阶段,这意味着它仍然是未经编辑的原始版本。
import numpy as np
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.pivot_table('survived', index='sex', columns='class')结果是:
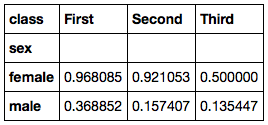
但是,如果我现在尝试使用margins关键字添加总计,则会发生以下错误:
titanic.pivot_table('survived', index='sex', columns='class', margins=True)
TypeError: cannot insert an item into a CategoricalIndex that is not already an existing category知道是什么导致的吗?
版本信息:
- Python 3.4.2
- 熊猫0.16.2
- 矮胖1.9.2
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-09-04 16:13:04
这似乎是由于大熊猫0.15和0.16之间的变化。在以前的版本中,泰坦尼克数据集具有这样的dtype:
In [1]: import pandas, seaborn
In [2]: pandas.__version__
'0.15.2'
In [3]: titanic = seaborn.load_dataset('titanic')
In [4]: titanic.dtypes
Out[4]:
survived int64
pclass int64
sex object
age float64
sibsp int64
parch int64
fare float64
embarked object
class object
who object
adult_male bool
deck object
embark_town object
alive object
alone bool
dtype: object新的熊猫:
In [1]: import pandas, seaborn
In [2]: pandas.__version__
'0.16.2'
In [3]: titanic = seaborn.load_dataset('titanic')
In [4]: titanic.dtypes
Out[4]:
survived int64
pclass int64
sex object
age float64
sibsp int64
parch int64
fare float64
embarked object
class category
who object
adult_male bool
deck category
embark_town object
alive object
alone bool
dtype: object有几个列会自动转换为分类,这会导致这个错误。这本书目前还没有出版,也没有编辑;我将确保用最新版本进行测试,并在出版前修复这些类型的错误。
现在,这里有一个解决办法:
In [5]: titanic['class'] = titanic['class'].astype(object)
In [6]: titanic.pivot_table('survived', index='sex', columns='class', margins=True)
Out[6]:
class First Second Third All
sex
female 0.968085 0.921053 0.500000 0.742038
male 0.368852 0.157407 0.135447 0.188908
All 0.629630 0.472826 0.242363 0.383838编辑:我把这个作为一个问题提交给熊猫项目:https://github.com/pydata/pandas/issues/10989
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/32400279
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号