
R中分层聚类算法编程的教学方法
我正在准备一个关于R机器学习的讲座,我想以层次聚类为例。我在这里发现了一个非常有教育意义的页面:html/层次结构.html
它以以下距离表开始(在读取数据时,请将NA作为列/行名称,也请参见下面的内容):
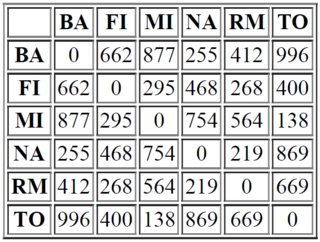
最短的距离是138在MI和TO之间,因此我们希望将这些列和行合并到一个新的列/行MI/TO中,这个新的复合对象MI/TO到所有剩余城市的距离等于原始城市MI或TO中的一个城市的最短距离,例如MI/TO到RM是564 (来自MI),因为这比669 (来自TO)。(这种聚合方式称为单连锁聚类)。所以我们有一张新桌子:
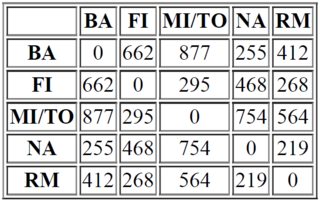
我的问题
我开始用R编写这段代码,很快就发现代码变得越来越杂乱无章--远远不能被羽翼未丰的程序员理解。您知道一种方法或包,您可以用它以自然和直观的方式进行这种数据操作吗?
这是R中的起始表:
D <- matrix(c(0,662,877,255,412,996,
662,0,295,468,268,400,
877,295,0,754,564,138,
255,468,754,0,219,869,
412,268,564,219,0,669,
996,400,138,869,669,0), ncol=6, byrow=T)
rownames(D) <- colnames(D) <- c("BA","FI","MI","Na","RM","TO")
D
## BA FI MI Na RM TO
## BA 0 662 877 255 412 996
## FI 662 0 295 468 268 400
## MI 877 295 0 754 564 138
## Na 255 468 754 0 219 869
## RM 412 268 564 219 0 669
## TO 996 400 138 869 669 0回答 2
Stack Overflow用户
发布于 2015-08-28 08:46:30
内置函数"hclust“已经是一个很好的工作函数。
hc1 = hclust(as.dist(D), method = "single")
hc1$merge
plot(hc1)如果你想澄清的话,我可以详细描述。
按照hclust的逻辑,您可以尝试:
savemat = list()
D1 = D; diag(D1) = Inf # a trick to make zero a infinity
m = 1
while(dim(D1)[1] > 2) {
# get the location of minimum distance
minloc = which(D1 == min(D1), arr.ind = T)[1,]
# make a two-column matrix then find out the minimum value of each row
u = apply(cbind(D1[minloc[2],],D1[minloc[1],]),1,min)
# updating the matrix
D1[minloc[2],] = u
D1[,minloc[2]] = u
u = paste0(rownames(D1)[minloc[2]],'/',rownames(D1)[minloc[1]])
rownames(D1)[minloc[2]] = u
colnames(D1)[minloc[2]] = u
# deleting the merged column/row
D1 = D1[-minloc[1],-minloc[1]]
diag(D1) = Inf
# save the steps into a list element mth
savemat[[m]] = D1
m = m + 1
}
savematStack Overflow用户
发布于 2015-08-28 09:47:45
更新的代码作为递归函数和单独的打印函数,以便更好地跟踪正在发生的事情。与hcl(<data.frame>,<log_level>)一起使用。对于最终结果,日志级别可以为0,打印中间数据集的日志级别为1,打印每个步骤的日志级别为2。
# To be allowed to add column later, don't know a better way than coercing to data.frame
d <- data.frame(D,stringsAsFactors=F)
myprt <- function(message,var) {
print(message)
print(var)
}
hcl <- function(d,prt=0) {
if (prt) myprt("Starting dataset:",d)
# 1) Get the shortest distance informations:
Ref <- which( d==min(d[d>0]), useNames=T, arr.ind=T )
if (prt>1) myprt("Ref is:",Ref)
# 2) Subset the original entry to remove thoose towns:
res <- d[-Ref[,1],-Ref[,1]]
if (prt>1) myprt("Res is:", res)
# 3) Get the subset for the two nearest towns:
tmp <- d[-Ref[,1],Ref[,1]]
if (prt>1) myprt("Tmp is:",tmp)
# 4) Get the vector of minimal distance from original dataset with the two town (row by row on t)
dists <- apply( tmp, 1, function(x) { x[x==min(x)] } )
#dists <- tmp[ tmp == pmin( tmp[,1], tmp[,2] ) ]
if (prt>1) myprt("Dists is:",dists)
# 5) Let's build the resulting matrix:
tnames <- paste(rownames(Ref),collapse="/") # Get the names of town to the new name
if (length(res) == 1) {
# Nothing left in the original dataset just concat the names and return
tnames <- paste(c(tnames,names(dists)),collapse="/")
Finalres <- data.frame(tnames = dists) # build the df
names(Finalres) <- rownames(Finalres) <- tnames # Name it
if (prt>0) myprt("Final result:",Finalres)
return(Finalres) # Last iteration
} else {
Finalres <- res
Finalres[tnames,tnames] <- 0 # Set the diagonal to 0
Finalres[is.na(Finalres)] <- dists # the previous assignment has set NAs, replae them by the dists values
if (prt>0) myprt("Dataset before recursive call:",Finalres)
return(hcl(Finalres,prt)) # we're not at end, recall ourselves with actual result
}
}另一个按步骤提出的想法:
# To be allowed to add column later, don't know a better way than coercing to data.frame
d <- data.frame(D,stringsAsFactors=F)
# 1) Get the shortest distance informations:
Ref <- which( d==min(d[d>0]), useNames=T, arr.ind=T )
# 2) Subset the original entry to remove thoose towns:
res <-d[-Ref[,1],-Ref[,1]]
# 3) Get the subset for the two nearest towns:
tmp <- d[-Ref[,1],Ref[,1]]
# 4) Get the vector of minimal distance from original dataset with the two town (row by row on tpm), didn't find a proper way to avoid apply
dists <- apply( tmp, 1, function(x) { x[x==min(x)] } )
dists <- dists <- tmp[ tmp == pmin( tmp[,1], tmp[,2] ) ]
# 5) Let's build the resulting matrix:
tnames <- paste(rownames(Ref),collapse="/") # Get the names of town to the new name
Finalres <- res
Finalres[tnames,tnames] <- 0 # Set the diagonal to 0
Finalres[is.na(Finalres)] <- dists # the previous assignment has set NAs, replae them by the dists values输出:
> Finalres
BA FI Na RM TO/MI
BA 0 662 255 412 877
FI 662 0 468 268 295
Na 255 468 0 219 754
RM 412 268 219 0 564
TO/MI 877 295 754 564 0以及每一步的输出:
> #Steps:
>
> Ref
row col
TO 6 3
MI 3 6
> res
BA FI Na RM
BA 0 662 255 412
FI 662 0 468 268
Na 255 468 0 219
RM 412 268 219 0
> tmp
TO MI
BA 996 877
FI 400 295
Na 869 754
RM 669 564
> dists
[1] 877 295 754 564这里有很多对象复制可以避免,以节省性能,我让它有一个更好的一步一步的视图。
https://stackoverflow.com/questions/32266666
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号