
诊断并行单片性能
我使用Attoparsec库编写了一个Bytestring解析器:
import qualified Data.ByteString.Char8 as B
import qualified Data.Attoparsec.ByteString.Char8 as P
parseComplex :: P.Parser Complex我的目的是使用这个解析大文件(> 5GB),因此实现懒洋洋地使用这个解析器:
import qualified Data.ByteString.Lazy.Char8 as LB
import qualified Data.Attoparsec.ByteString.Lazy as LP
extr :: LP.Result a -> a
main = do
rawData <- liftA LB.words (LB.readFile "/mnt/hgfs/outputs/out.txt")
let formatedData = map (extr.LP.parse parseComplex) rawData
...在带有-O2和-s标志的测试文件上执行此操作,我看到:
3,509,019,048 bytes allocated in the heap
2,086,240 bytes copied during GC
58,256 bytes maximum residency (30 sample(s))
126,240 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 6737 colls, 0 par 0.03s 0.03s 0.0000s 0.0001s
Gen 1 30 colls, 0 par 0.00s 0.00s 0.0001s 0.0002s
INIT time 0.00s ( 0.00s elapsed)
MUT time 0.83s ( 0.83s elapsed)
GC time 0.04s ( 0.04s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 0.87s ( 0.86s elapsed)
%GC time 4.3% (4.3% elapsed)
Alloc rate 4,251,154,493 bytes per MUT second
Productivity 95.6% of total user, 95.8% of total elapsed由于我是独立地在列表上映射函数,所以我认为这段代码可能会受益于并行化。我以前从未在Haskell中做过类似的事情,但在处理Control.Monad.Par库时,我编写了一个简单、天真、静态的解析函数,我认为它可以并行地映射我的解析:
import Control.Monad.Par
parseMap :: [LB.ByteString] -> [Complex]
parseMap x = runPar $ do
let (as, bs) = force $ splitAt (length x `div` 2) x
a <- spawnP $ map (extr.LP.parse parseComplex) as
b <- spawnP $ map (extr.LP.parse parseComplex) bs
c <- get a
d <- get b
return $ c ++ d我对这个函数没有太多的期望,但是并行的性能要比顺序计算差得多。下面是用-O2 -threaded -rtsopts编译并用+RTS -s -N2执行的主要函数和结果
main = do
rawData <- liftA LB.words (LB.readFile "/mnt/hgfs/outputs/out.txt")
let formatedData = parseMap rawData
... 3,641,068,984 bytes allocated in the heap
356,490,472 bytes copied during GC
82,325,144 bytes maximum residency (10 sample(s))
14,182,712 bytes maximum slop
253 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 4704 colls, 4704 par 0.50s 0.25s 0.0001s 0.0006s
Gen 1 10 colls, 9 par 0.57s 0.29s 0.0295s 0.1064s
Parallel GC work balance: 19.77% (serial 0%, perfect 100%)
TASKS: 4 (1 bound, 3 peak workers (3 total), using -N2)
SPARKS: 0 (0 converted, 0 overflowed, 0 dud, 0 GC'd, 0 fizzled)
INIT time 0.00s ( 0.00s elapsed)
MUT time 1.11s ( 0.72s elapsed)
GC time 1.07s ( 0.54s elapsed)
EXIT time 0.02s ( 0.02s elapsed)
Total time 2.20s ( 1.28s elapsed)
Alloc rate 3,278,811,516 bytes per MUT second
Productivity 51.2% of total user, 88.4% of total elapsed
gc_alloc_block_sync: 149514
whitehole_spin: 0
gen[0].sync: 0
gen[1].sync: 32正如您所看到的,在并行情况下似乎有很多垃圾收集器活动,并且负载非常不平衡。我使用线程范围分析了执行过程,得到了以下内容:
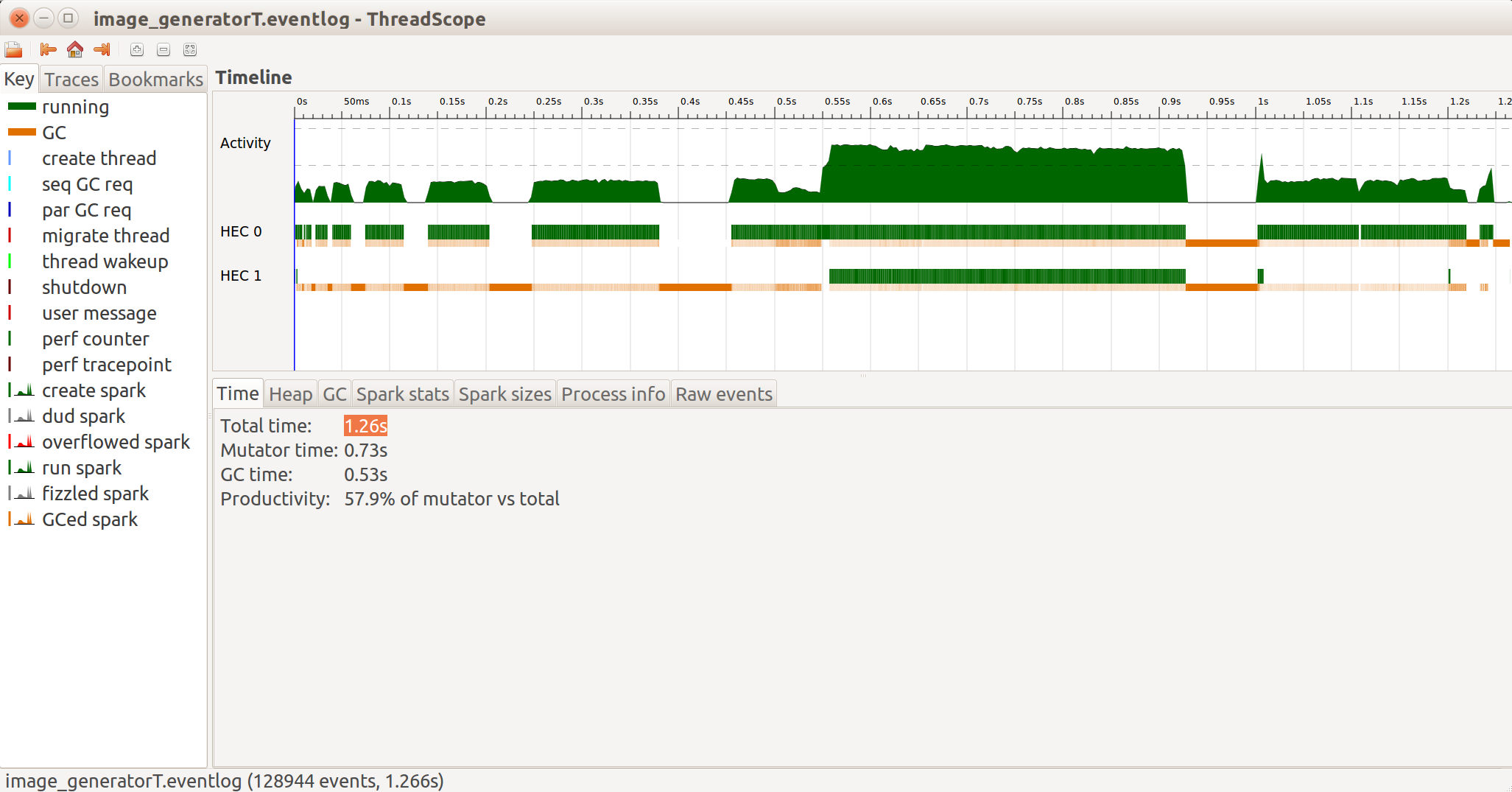
我可以清楚地看到,在HEC 1上运行的垃圾收集器正在中断HEC 2上的计算。而且,HEC 1的分配工作量明显少于HEC 2。作为一个测试,我试图调整两个拆分列表的相对大小,以重新平衡负载,但在这样做之后,我发现程序的行为没有明显的差异。我还尝试在不同大小的输入上运行这个程序,使用更大的最小堆分配,并且只使用Control.Monad.Par库中包含的Control.Monad.Par函数,但这些工作也不会对结果产生影响。
我假设某个地方有一个空间泄漏,可能是来自let (as,bs) = ...分配,因为在并行情况下,内存使用量要高得多。这就是问题所在吗?如果是的话,我该如何解决这个问题呢?
编辑:按建议手动分割输入数据,我现在看到的是时间上的一些小改进。对于6m点输入文件,我手动将文件拆分为两个3m点文件和三个2m点文件,并分别使用2核和3核重新运行代码。粗略的时间表如下:
1核心:6.5 s
2核心:5.7 s
3核心:4.5 s
新的线程范围配置文件如下所示:
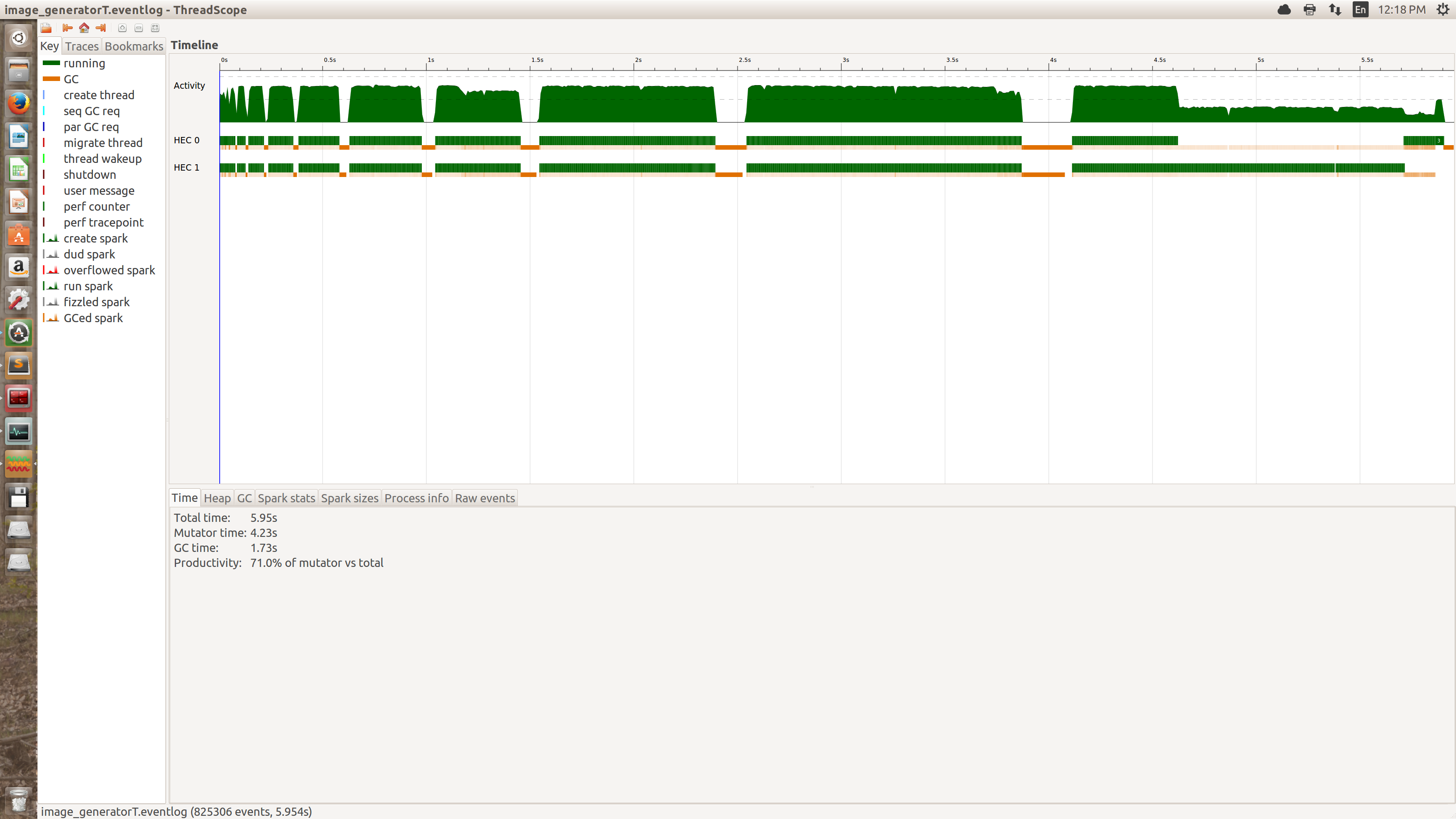
最初的奇怪行为已经消失,但现在仍然有一些,在我看来,似乎还有一些明显的负载平衡问题。
回答 1
Stack Overflow用户
发布于 2015-08-04 01:16:53
首先,我建议参考您的代码评审,发布(link),为人们提供更多关于您想要做的事情的背景信息。
您的基本问题是强制Haskell使用length x将整个文件读入内存。您想要做的是在结果中进行流,使文件在任何时候都在内存中。
您所拥有的是一个典型的map--减少计算,因此,要将工作负载分成两部分,我的建议是:
- 打开输入文件两次,创建两个文件句柄。
- 将第二个句柄放置在文件的“中间”。
- 创建两个计算-每个文件句柄一个。
- 第一个计算将从其句柄读取到“中间”;第二个计算将从其句柄读取到文件的末尾。
- 每次计算都会创建一个
Vector Int - 当每一次计算完成后,我们将两个向量组合在一起(将向量元素按顺序加起来)。
当然,文件的“中间”是靠近文件中间的一行的开头。
棘手的部分是步骤4,因此为了简化操作,让我们假设输入文件已经被分割成两个独立的文件part1和part2。那么您的计算结果可能如下所示:
main = do
content1 <- LB.readFile "part1"
content2 <- LB.readFile "part2"
let v = runPar $ do a <- spawnP $ computeVector content1
b <- spawnP $ computeVector content2
vec1 <- get a
vec2 <- get b
-- combine vec1 and vec2
let vec3 = ...vec1 + vec2...
return vec3
...您应该尝试这种方法并确定加速比是什么。如果它看起来不错,那么我们就可以知道如何将一个文件实际上分割成多个部分,而不必实际复制数据。
注意-我没有实际运行这个,所以我不知道是否有奇怪的w.r.t。懒惰-IO和标准单子,但这种想法在某种形式上应该是可行的。
https://stackoverflow.com/questions/31798004
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号