
快速空间分割启发式?
我有一个由N线段填充的(子)空间。这些线段总是凸多边形的一部分。看起来可能是这样的:
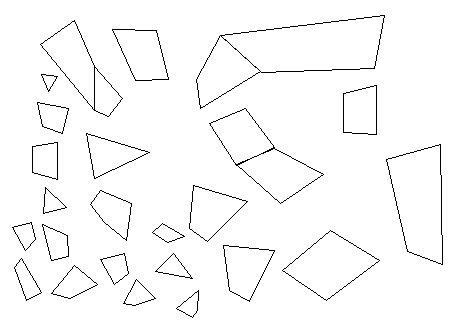
我想要做的是开发一个启发式的方法来选择一个线段来分割空间。所选段的支持线随后将分割空间。有两个相互矛盾的启发因素:
- 线段应该平分空间;子空间A中的线段应该和B子空间中的线段一样多(balance)
- 线段的支撑线应尽可能少地相交(分裂)其他线段(自由度)
举个例子:
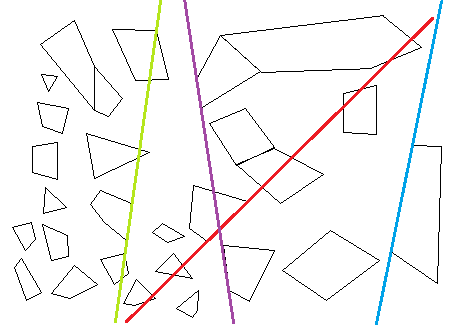
蓝线:完美的自由,很糟糕的平衡。
红线:非常糟糕的自由,平庸的平衡。
绿线:糟糕的自由,极好的平衡。
紫色线条:很好的自由,体面的平衡。
在上面的例子中,组合启发式可能会选择紫色线。
现在,我可以循环遍历每个线段,并将其与其他每一个线段进行比较(查看它们相交的部分以及它们在两边的平衡程度)。但这需要O(N^2)操作。我更喜欢在O(N log N)中运行的东西。
对O(N log N)算法有什么想法吗?该算法可以遍历线段并给出分数?我的一个想法是对这些片段进行三次排序,并形成一些象限:
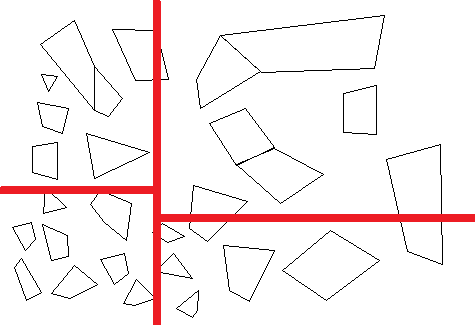
象限中心给出了大多数线段所在的位置。因此,也许可以用它们来找到这个中心附近的一个线段,并检查它的方向是否可以参考象限。不知何故。这会给出一个很好的平衡分数。
对于交集,我考虑为段创建包围框,并将它们排序为树,从而可能加快交集估计?
一些额外的提示(我的输入数据在很多时候看起来是什么样的)
- 大部分线段是轴向的(纯X或Y取向)
- 与它们的传播相比,大多数片段都很小。
感谢任何新的想法或见解--数据结构或策略的最小提示将极大地帮助你!
回答 1
Stack Overflow用户
发布于 2015-08-16 17:33:52
溶液
我发现了一个对我的BSP树非常有用的启发式方法,它也非常有趣。在下面的代码中,我首先尝试使用AABB树来问“这一行是哪些段相交”。但是即使这样做也太慢了,所以最后我只使用了一个代价高昂的初始O(N^2)比较算法,该算法在BSP树构建时快速加速,使用了一个有点聪明的观察结果!
- 让每个BSP节点跟踪它仍然保留在子空间中的线段(以及它必须从哪个分配器中选择)。
- 让每个段有四个与其相关联的值:
posCount、negCount、introduced和saved。让它也有一个对另一个段的partner引用,以防它被分割(否则是null)。 - 使用以下
O(N^2)algo在根节点(即所有拆分器)初始化拆分器:
算法calcRelationCounts(splitters S):O(N^2)
for all splitters s in S
s.posCount = s.negCount = s.introduced = s.saved = 0
for all splitters vs in S
if (s == vs) continue
if vs is fully on the positive side of the plane of s
s.posCount++
else if vs is fully on the negative side of the plane of s
s.negCount++
else if vs intersects the plane of s
s.negCount++, s.posCount++, s.introduced++
else if vs is coplanar with s
s.saved++- 对于仍保留拆分器的每个节点,请选择最大限度地实现以下目标的节点:
算法evaluate(...)其中treeDepth = floor(log2(splitterCountAtThisNode)):O(1)
evaluate(posCount, negCount, saved, introduced, treeDepth) {
float f;
if (treeDepth >= EVALUATE_X2) {
f = EVALUATE_V2;
} else if (treeDepth >= EVALUATE_X1) {
float r = treeDepth - EVALUATE_X1;
float w = EVALUATE_X2 - EVALUATE_X1;
f = ((w-r) * EVALUATE_V1 + r * EVALUATE_V2) / w;
} else {
f = EVALUATE_V1;
}
float balanceScore = -f * BALANCE_WEIGHT * abs(posCount - negCount);
float freedomScore = (1.0f-f) * (SAVED_WEIGHT * saved - INTRO_WEIGHT * introduced);
return freedomScore + balanceScore;
}下面是我的优化算法使用的神奇数字:
#define BALANCE_WEIGHT 437
#define INTRO_WEIGHT 750
#define SAVED_WEIGHT 562
#define EVALUATE_X1 3
#define EVALUATE_X2 31
#define EVALUATE_V1 0.0351639f
#define EVALUATE_V2 0.187508f- 使用此拆分器作为此节点的拆分器,称为SEL。然后,将该节点上的所有拆分器划分为三组:
positives、negatives和remnants。
算法distributeSplitters()
for all splitters s at this node
s.partner = null
if s == SEL then add s to "remnants"
else
if s is fully on the positive side of SEL
add s to "positives"
else if s is fully on the negative side of SEL
add s to "negatives
else if s intersects SEL
split s into two appropriate segments sp and sn
sp.partner = sn, sn.partner = sp
add sn to "negatives", sp to "positives" and s to "remnants"
else if s coplanar with SEL
add s to "remnants"
// the clever bit
if (positives.size() > negatives.size())
calcRelationCounts(negatives)
updateRelationCounts(positives, negatives, remnants)
else
calcRelationCounts(positives)
updateRelationCounts(negatives, positives, remnants)
add positives and negatives to appropriate child nodes for further processing我在这里意识到的聪明之处是,通常,特别是使用上述启发式的第一对分裂,会产生非常不平衡的分裂(但非常自由)。问题是,当O(N^2) + O((N-n)^2)" + ...很小的时候,它是很可怕的!相反,我意识到我们不需要这样做,我们可以困难地重新计算取O(n^2)的最小的拆分,而不是坏的,然后简单地迭代每个位拆分器,从较小的拆分部分减去计数,这只需要比O(N^2)好得多的O(Nn)!下面是updateRelationCounts()的代码
算法updateRelationCounts()
updateRelationCounts(toUpdate, removed, remnants) {
for all splitters s in toUpdate
for all splitters vs in removed, then remnants
if vs has a partner
if the partner intersects s
s.posCount++, s.negCount++, s.introduced++
else if the partner is fully on the positive side of s
s.posCount++
else if the partner is fully on the negative side of s
s.negCount++
else if the partner is coplanar with s
s.saved++
else
if vs intersects s
s.posCount--, s.negCount--, s.introduced--
else if vs is fully on the positive side of s
s.posCount--
else if vs is fully on the negative side of s
s.negCount--
else if vs is coplanar with s
s.saved--我现在已经仔细地测试了这一点,而且它的逻辑似乎是正确的,因为更新正确地修改了posCount等等,这样它们就会与如果它们再次被重新计算的话是相同的!
https://stackoverflow.com/questions/31794445
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号