
无EM分布高斯混合模型的Matlab: EM
我必须在给定的数据集上使用四个分量来训练高斯混合模型。该装置是三维的,包含300个样本。
问题是,我不能使用日志似然来检查收敛性,因为它是-Inf。这是在计算责任公式中的高斯值时得到的四舍五入零值的结果(参见E-步骤)。
到目前为止,你能告诉我我对EM算法的实现是否正确吗?以及如何解释四舍五入的零值问题?
下面是EM算法的实现(一次迭代):
首先,我使用初始化了,即组件的均值和协方差:
load('data1.mat');
X = Data'; % 300x3 data set
D = size(X,2); % dimension
N = size(X,1); % number of samples
K = 4; % number of Gaussian Mixture components
% Initialization
p = [0.2, 0.3, 0.2, 0.3]; % arbitrary pi
[idx,mu] = kmeans(X,K); % initial means of the components
% compute the covariance of the components
sigma = zeros(D,D,K);
for k = 1:K
sigma(:,:,k) = cov(X(idx==k,:));
end对于E步骤,我使用以下公式来计算责任
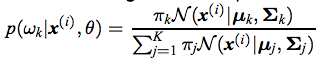
以下是相应的代码:
gm = zeros(K,N); % gaussian component in the nominator -
% some values evaluate to zero
sumGM = zeros(N,1); % denominator of responsibilities
% E-step: Evaluate the responsibilities using the current parameters
% compute the nominator and denominator of the responsibilities
for k = 1:K
for i = 1:N
% HERE values evalute to zero e.g. exp(-746.6228) = -Inf
gm(k,i) = p(k)/sqrt(det(sigma(:,:,k))*(2*pi)^D)*exp(-0.5*(X(i,:)-mu(k,:))*inv(sigma(:,:,k))*(X(i,:)-mu(k,:))');
sumGM(i) = sumGM(i) + gm(k,i);
end
end
res = zeros(K,N); % responsibilities
Nk = zeros(4,1);
for k = 1:K
for i = 1:N
res(k,i) = gm(k,i)/sumGM(i);
end
Nk(k) = sum(res(k,:));
endNk(k)是用M阶的公式计算的.
M步进
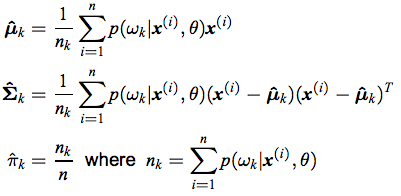
% M-step: Re-estimate the parameters using the current responsibilities
mu = zeros(K,3);
for k = 1:K
for i = 1:N
mu(k,:) = mu(k,:) + res(k,i).*X(k,:);
sigma(:,:,k) = sigma(:,:,k) + res(k,i).*(X(k,:)-mu(k,:))*(X(k,:)-mu(k,:))';
end
mu(k,:) = mu(k,:)./Nk(k);
sigma(:,:,k) = sigma(:,:,k)./Nk(k);
p(k) = Nk(k)/N;
end现在,为了检查收敛性,使用以下公式计算log-似然:
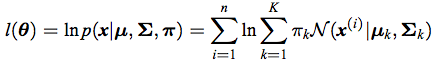
% Evaluate the log-likelihood and check for convergence of either
% the parameters or the log-likelihood. If not converged, go to E-step.
loglikelihood = 0;
for i = 1:N
for k = 1:K
loglikelihood = loglikelihood + log(gm(k,i));
end
endloglikelihood是-Inf,因为E-步骤中的一些gm(k,i)值为零.因此,日志显然是负无穷大的。
我该如何解决这个问题?
可以通过提高Matlab的精度来解决这个问题吗?
或者我的实现有什么问题吗?
回答 1
Stack Overflow用户
发布于 2015-07-29 17:40:32
根据公式,你应该计算gm量之和的对数。(因此,log(sum(gm(i,:)。在k分量中,至少有一个可能大于0。希望这能解决你的问题。
另一个非常普遍的观点是,当数字太大而不能将函数作为指数函数时,当您确定使用的是正确的公式时,您总是可以尝试使用数量的日志。但是您不需要在这里这样做,因为0是exp(-746)的一个很好的近似;)
https://stackoverflow.com/questions/31631930
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号