
Rethinkdb SIGTERM,关闭
我在码头运行RethinkDB。在我们移到一个新的数据中心之前,一切都进行得很顺利(但我不确定这是否与移动有关)。下面是正在发生的事情。
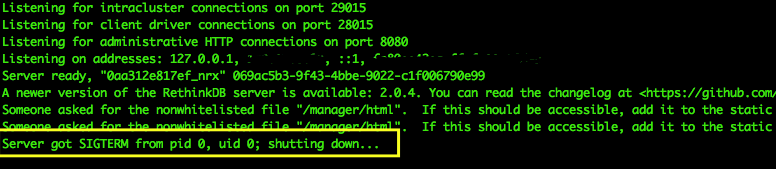
我启动rethinkdb容器,一切运行良好一段时间。经过一段时间(在一个小时或更长时间之间变化),我在Docker日志中看到了以下内容(以黄色突出显示):
我完全不知道它为什么随机地从系统接收到一个SIGTERM。任何想法都将不胜感激!
编辑:我正在为SIGTERM添加日志文件的片段。根据时间戳,似乎没有任何一种模式。
2015-07-15T16:15:02.888762613 663165.661585s notice: Server got SIGTERM from pid 0, uid 0; shutting down...
2015-07-17T17:02:11.562306701 13322.914561s notice: Server got SIGTERM from pid 0, uid 0; shutting down...
2015-07-19T18:31:12.499022237 96786.220054s notice: Server got SIGTERM from pid 0, uid 0; shutting down...
2015-07-20T13:52:44.493304030 69690.608865s notice: Server got SIGTERM from pid 0, uid 0; shutting down...编辑2:我在Docker之外运行RethinkDB,我在日志中看到了这一点:错误:工作进程未能与主进程重新同步。不知道是不是有什么需要关心的。它似乎根本不影响RethinkDB实例(所有客户端都保持连接)。
2015-07-21T06:53:10.663375859 0.116098s info: Automatically using cache size of 10702 MB
2015-07-21T06:53:10.676277261 0.128998s notice: Listening for intracluster connections on port 29015
2015-07-21T06:53:10.684504354 0.137225s notice: Listening for client driver connections on port 28015
2015-07-21T06:53:10.685485550 0.138206s notice: Listening for administrative HTTP connections on port 8080
2015-07-21T06:53:10.686313405 0.139034s notice: Listening on addresses: 127.0.0.1, 172.17.42.1, 192.151.151.122, ::1, fe80::1879:43ff:fe5e:bdb2%34, fe80::62eb:69ff:fe07:d986%2, fe80::b837:f2ff:fecd:d5cd%4
2015-07-21T06:53:10.686316632 0.139037s notice: Server ready, "0aa312e817ef_nrx" 069ac5b3-9f43-4bbe-9022-c1f006790e99
2015-07-21T06:53:11.558116243 1.010837s error: worker process failed to resynchronize with main process
2015-07-21T06:53:11.558122179 1.010843s notice: A newer version of the RethinkDB server is available: 2.0.4. You can read the changelog at <https://github.com/rethinkdb/rethinkdb/releases>.编辑3:我在这里发现了另一个问题,我认为这可能是真正的问题。重新思考适配器(在应用程序中)保持与DB服务器的连接,这将耗尽系统中可用的文件描述符/端口。下面是一个lsof的打印输出示例。注意,,这只是一个简短的列表。当多个人使用该系统时,有成百上千个系统处于打开状态。
node 11633 [username_ommitted] 201u IPv4 0x53153575d33d64bb 0t0 TCP 192.168.1.142:61041->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 202u IPv4 0x53153575d33fa65b 0t0 TCP 192.168.1.142:61053->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 203u IPv4 0x53153575dd6a5d8b 0t0 TCP 192.168.1.142:61043->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 204u IPv4 0x53153575bff6717b 0t0 TCP 192.168.1.142:61044->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 206u IPv4 0x53153575d33e54bb 0t0 TCP 192.168.1.142:61049->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 207u IPv4 0x53153575d33ef4bb 0t0 TCP 192.168.1.142:61050->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 208u IPv4 0x53153575d33f2a4b 0t0 TCP 192.168.1.142:61051->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 209u IPv4 0x53153575c333a17b 0t0 TCP 192.168.1.142:61054->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 210u IPv4 0x53153575d33b47fb 0t0 TCP 192.168.1.142:61056->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 211u IPv4 0x53153575d33de17b 0t0 TCP 192.168.1.142:61057->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 212u IPv4 0x53153575d33f065b 0t0 TCP 192.168.1.142:61058->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 213u IPv4 0x53153575bff67a4b 0t0 TCP 192.168.1.142:61059->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 216u IPv4 0x53153575dd68f31b 0t0 TCP 192.168.1.142:61062->[RETHINK_IP]:28015 (ESTABLISHED)
node 11633 [username_ommitted] 217u IPv4 0x53153575dd675a4b 0t0 TCP 192.168.1.142:61063->[RETHINK_IP]:28015 (ESTABLISHED)回答 1
Stack Overflow用户
发布于 2017-06-06 14:56:59
我也遇到了同样的问题,并认为这是由于没有关闭数据库连接(正如您在EDIT 3中所注意到的)。我在一个高速公路应用程序中使用RethinkDB,并遵循来自这里的中间件示例,但我总是在没有调用next()的情况下终止控制器中的请求响应周期,这意味着永远无法到达closeConnection中间件。
https://stackoverflow.com/questions/31518078
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号