
在查询结果中包括第一组和最后一组
在查询结果中包括第一组和最后一组
提问于 2015-07-14 13:05:44
在下面的ERD中
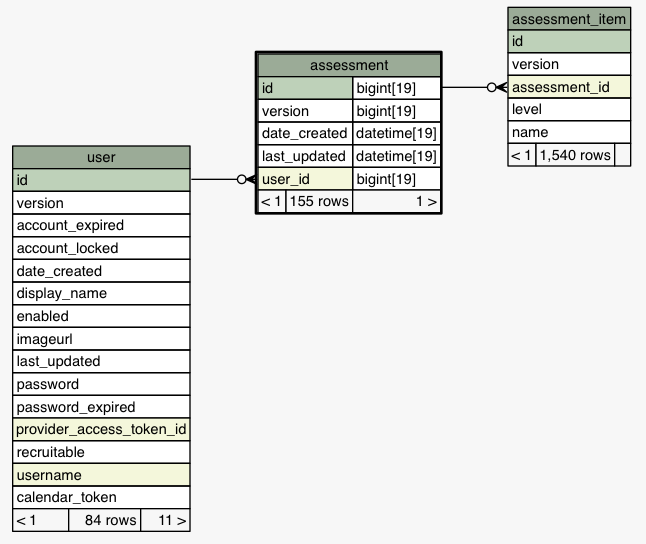
assessment表示用户完成的测试。每个评估由多个项目组成,level表示它们在每个项目上的得分。
我需要计算用户在他们最早的评估和最新的评估中的平均分数之间的差异,但是我真的很挣扎。
我可以得到每个评估的平均分数
SELECT a.user_id,
a.date_created,
avg(ai.level)
FROM assessment a
JOIN assessment_item ai ON a.id = ai.assessment_id
GROUP BY a.user_id, a.date_created
ORDER BY 1;此查询返回数据,如
user_id, date_created, avg_score
10, "2015-07-13 18:09:59", 3.0000
11, "2015-07-13 18:09:59", 3.0000
13, "2015-07-13 18:26:00", 2.0000
13, "2015-07-13 18:27:28", 6.0000
13, "2015-07-13 19:04:58", 3.0000我可以(以编程方式)迭代此查询返回的结果,忽略任何“中间”评估或只完成一个评估的用户的结果,但我认为应该有一种方法来改进查询,使其返回的数据更接近我所需的数据。
回答 2
Stack Overflow用户
回答已采纳
发布于 2015-07-14 13:18:17
可能最简单的方法是使用substring_index()/group_concat()技巧:
SELECT user_id,
substring_index(group_concat(levavg order by date_created), ',', 1) as first_avg,
substring_index(group_concat(levavg order by date_created desc), ',', 1) as lasst_avg,
FROM (SELECT a.user_id, a.date_created, avg(ai.level) as levavg
FROM assessment a JOIN
assessment_item ai
ON a.id = ai.assessment_id
GROUP BY a.user_id, a.date_created
) ua
GROUP BY user_id
HAVING COUNT(*) > 1
ORDER BY 1;Stack Overflow用户
发布于 2015-07-14 16:50:45
EXISTS救出了一切!(第一条记录没有先前的记录;最后一条记录没有下一条记录;出口产生一个布尔值,可以进行比较)
未经测试,因为我没有测试数据
SELECT a.user_id
, a.date_created
, avg(ai.level)
FROM assessment a
JOIN assessment_item ai ON a.id = ai.assessment_id
WHERE EXISTS ( SELECT * FROM assessment xx
WHERE xx.user_id = a.userid
AND xx.date_created < a.date_created
)
<> EXISTS ( SELECT * FROM assessment xx
WHERE xx.user_id = a.userid
AND xx.date_created > a.date_created
)
GROUP BY a.user_id, a.date_created
ORDER BY 1, 2;页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/31407498
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号