
R中RPart图中的胡乱输出
R中RPart图中的胡乱输出
提问于 2015-07-13 06:50:20
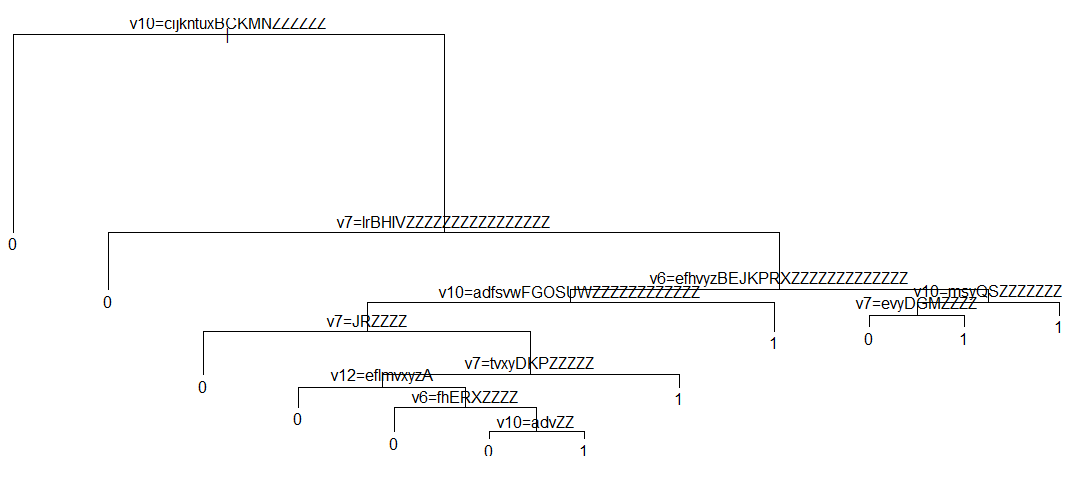
我试图在一个包含26个变量的数据集上运行一个决策树( RPart in R ),将结果分类为0或1。该模型的准确率为81%,当我继续绘制该树时,我得到了非常混乱的变量分裂值。例: v10包含一些国家的列表,比如美国、英国、印度等,但是这里的情节显示为一些荒谬的价值。v7这里有一个URL列表,v12在我的数据集中有一些定量的数字,但是树值看起来很糟糕。
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-07-21 18:28:44
该算法将每个因素的级别替换为字母中的小写和大写字母。如果因子中有超过56个级别,则重复Z字母,因此不建议使用超过56个级别的因素作为rpart模型的输入。
但是,可以避免不必要的“胡言乱语”输出:如果您使用的是plot() + text(),请尝试在text()函数中使用“漂亮”参数。示例:
plot(tree)
text(tree, pretty=1)其他输出函数有其特定的参数。例如,"labels()“具有"minlength”参数:
labels(tree)
labels(tree,minlength=0)我希望这能帮上忙。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/31377019
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号