
卡桑德拉工具的使用-应力
我想用1、2、3和4个实例对Cassandra集群进行基准测试。所以我在节点的one上运行了cassandra应力工具。基准测试显示了奇怪的结果,请参见下面的图表(->单节点集群比2-/3-/4节点集群具有更多的操作/sek(当很少线程时)。
我的结果(x轴=线程,y轴=op/sek,集群中的dataset=nodes (1,2,3,4):
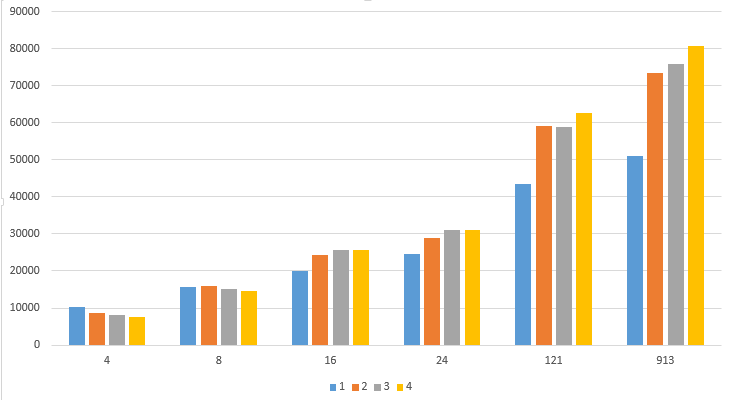
与来自结果的这个基准站点相比,我的结果似乎不正确。
我现在的问题是:如果我在集群的一台机器上运行以下命令,我是否正确地使用了该工具:
cassandra-stress write我也尝试过这样做,但没有任何效果:
cassandra-stress write -node ip1,ip2,...也见我的另一个问题这里。谢谢!
-编辑:吉姆的解决方案--
从C*-集群之外的其他EC2实例中运行cassandra工具,但是在同一个LAN中运行(这样您就可以使用内部ips 10.x.x.x)。我启动了一个1/2/4节点集群,其中包含4个独立的基准调用节点。每个命令都有以下命令之一:
第一篇文章:
cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1..1000000 -node ip1,ip2,ip3,ip4
cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1000001..2000000 -node ip1,ip2,ip3,ip4
cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=2000001..3000000 -node ip1,ip2,ip3,ip4
cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=3000001..4000000 -node ip1,ip2,ip3,ip4然后使用read命令读取这些数据:
cassandra-stress read n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1..1000000 -node ip1,ip2,ip3,ip4
cassandra-stress read n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1000001..2000000 -node ip1,ip2,ip3,ip4
cassandra-stress read n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=2000001..3000000 -node ip1,ip2,ip3,ip4
cassandra-stress read n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=3000001..4000000 -node ip1,ip2,ip3,ip4这里是阅读的结果
1 Node cluster: 149,000 ops/sec
2 Node cluster: 348,000 ops/sec
4 Node cluster: 480,000 ops/sec谢谢吉姆!
回答 1
Stack Overflow用户
发布于 2015-07-10 20:30:34
如果您只在一个节点上运行cassandra应力,那么我认为这将是预期的结果。一台机器无法饱和一个四节点集群,这将是一个瓶颈。
另外,如果您在一个cassandra节点上运行cassandra-stress,那么该节点将通过运行Cassandra和压力客户端双重加载。这将给该机器的CPU和网络连接带来额外的压力。
要真正了解集群吞吐量,您应该从集群之外的多台计算机(但在同一个LAN上)运行压力。
https://stackoverflow.com/questions/31336753
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号