
优化回路性能
我一直在分析代码中的一个瓶颈(下面显示的函数),这个瓶颈被调用了数百万次。我可以用一些技巧来提高表现。XXXs数据取自困倦。
使用visual 2013、/O2和其他典型的发行版设置编译。
indicies通常为0到20个值,其他参数大小相同(b.size() == indicies.size() == temps.size() == temps[k].size())。
1: double Object::gradient(const size_t j,
2: const std::vector<double>& b,
3: const std::vector<size_t>& indices,
4: const std::vector<std::vector<double>>& temps) const
5: 23.27s {
6: double sum = 0;
7: 192.16s for (size_t k : indices)
8: 32.05s if (k != j)
9: 219.53s sum += temps[k][j]*b[k];
10:
11: 320.21s return boost::math::isfinite(sum) ? sum : 0;
13: 22.86s }有什么想法吗?
谢谢你的小费伙计们。以下是我从这些建议中得到的结果:
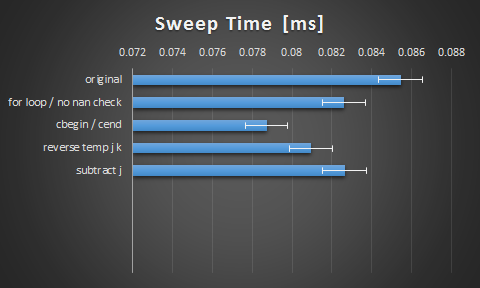
我发现切换到cbegin()和cend()有这么大的影响是很有趣的。我想编译器并没有那么聪明。我对此很满意,但我还是很好奇,通过展开或矢量化,这里是否还有更多的空间。
对于那些感兴趣的人,这里是我的isfinite(x)基准
boost::isfinite(x):
------------------------
SPEED: 761.164 per ms
TIME: 0.001314 ms
+/- 0.000023 ms
std::isfinite(x):
------------------------
SPEED: 266.835 per ms
TIME: 0.003748 ms
+/- 0.000065 ms回答 5
Stack Overflow用户
发布于 2015-06-27 00:26:01
如果您知道将满足条件(在每次迭代中您将满足k == j),则消除条件并用一个简单的条件存储替换返回条件。
double sum = -(temps[j][j]*b[j]);
for (size_t k : indices)
sum += temps[k][j]*b[k];
if (!std::isfinite(sum))
sum = 0.0;
return sum;基于范围的for仍然是新的,并不总是得到很好的优化。您还可以尝试:
const auto it = cend(indices);
for (auto it = cbegin(indices); it != end; ++it) {
sum += temps[*it][j]*b[*it];
}看看津贴会不会有变化。
Stack Overflow用户
发布于 2015-06-26 21:47:44
有两点很突出:
(a)提振::数学::是有限的,花费的时间相对较长。如果可能的话,试着用其他方法确定您的结果在有效范围内。
(b)将2D阵列作为嵌套矢量存储不是快速的方法。使临时数组成为一维数组并将行大小作为参数传递可能会更快。对于一个元素的访问,您必须自己进行索引计算。但是,由于其中一个索引(j)在循环中是恒定的,您可以在循环之前计算开始元素的索引,在循环内部只增加索引1,这可能会给您带来一些显著的改进。
Stack Overflow用户
发布于 2015-06-28 04:13:06
我相信如果你重新安排你的temps,你会得到很大的性能提升。下面的代码行
temps[k][j]*b[k]
迭代k的值(至少我理解它是)一个乘法,如果一个(转置)矩阵被一个向量。现在,访问一个元素temps[k][j]实际上包括读取temps[k],取消引用它(指向分配的向量的指针),然后读取它的[j]元素。
与使用vector<vector<double>不同,您还可以使用一维vector,而且,由于该函数是您的瓶颈,您可以以“转置”的方式将数据存储在其中。这意味着,以一种新格式访问temps[k][j]会变成temps[j * N + k],其中'N‘是j的范围。这样,您还可以更有效地利用缓存。
https://stackoverflow.com/questions/31082160
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号