
快速选择有时超时
快速选择有时超时
提问于 2015-06-26 09:11:19
我有执行简单选择的存储过程。每当我手动运行它时,它都会在第二个下运行。但是在生产(SQL S2数据库)中,它每12个任务运行一次--所以我认为有理由期望它在没有缓存数据的情况下每次运行“冷”。表演是非常不可预测的--有时需要5秒,有时需要30秒,有时甚至需要100秒。
SELECT被优化到最大限度(至少,据我所知)-我创建了包含select返回的所有列的过滤索引,所以执行计划中唯一的操作是索引扫描。估计行和实际行之间存在巨大差异:
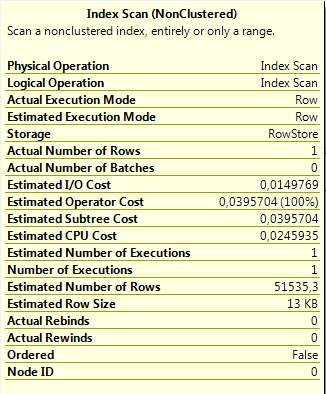
但是总的来说,这个查询看起来相当轻量级。我并不责怪环境(SQL ),因为有很多查询一直在执行,而这个查询是唯一有此性能问题的查询。
以下是SQL忍者愿意帮助的XML执行计划:http://pastebin.com/u5GCz0vW
编辑:
表结构:
CREATE TABLE [myproject].[Purchase](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ProductId] [nvarchar](50) NOT NULL,
[DeviceId] [nvarchar](255) NOT NULL,
[UserId] [nvarchar](255) NOT NULL,
[Receipt] [nvarchar](max) NULL,
[AppVersion] [nvarchar](50) NOT NULL,
[OSType] [tinyint] NOT NULL,
[IP] [nchar](15) NOT NULL,
[CreatedOn] [datetime] NOT NULL,
[ValidationState] [smallint] NOT NULL,
[ValidationInfo] [nvarchar](max) NULL,
[ValidationError] [nvarchar](max) NULL,
[ValidatedOn] [datetime] NULL,
[PurchaseId] [nvarchar](255) NULL,
[PurchaseDate] [datetime] NULL,
[ExpirationDate] [datetime] NULL,
CONSTRAINT [PK_Purchase] PRIMARY KEY CLUSTERED
(
[Id] ASC
)索引定义:
CREATE NONCLUSTERED INDEX [IX_AndroidRevalidationTargets3] ON [myproject].[Purchase]
(
[ExpirationDate] ASC,
[ValidatedOn] ASC
)
INCLUDE ( [ProductId],
[DeviceId],
[UserId],
[Receipt],
[AppVersion],
[OSType],
[IP],
[CreatedOn],
[ValidationState],
[ValidationInfo],
[ValidationError],
[PurchaseId],
[PurchaseDate])
WHERE ([OSType]=(1) AND [ProductId] IS NOT NULL AND [ProductId]<>'trial' AND ([ValidationState] IN ((1), (0), (-2))))数据可以被认为是敏感的,所以我不能提供样本。
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-06-26 12:02:31
因为查询只返回一个匹配项,所以我认为您应该将索引缩减到最小值。您可以通过键查找从聚集索引获取其余的列:
CREATE NONCLUSTERED INDEX [IX_AndroidRevalidationTargets3] ON [myproject].[Purchase]
(
[ExpirationDate] ASC,
[ValidatedOn] ASC
)
WHERE ([OSType]=(1) AND [ProductId] IS NOT NULL AND [ProductId]<>'trial' AND ([ValidationState] IN ((1), (0), (-2))))这并不能消除扫描,但它使索引更精简的快速读取。
编辑: OP声明Server忽略了精简索引.可以强制Server使用筛选器索引:
SELECT *
FROM [myproject].[Purchase] WITH (INDEX(IX_AndroidRevalidationTargets3))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/31069237
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号