
文档中属于一起的部分的分组算法
我有同一个文档的N个翻译,分为几个部分(让我们称之为诗句)。有些翻译省略了一些诗句。没有任何翻译包含所有的诗句。
我希望通过创建组来根据内容“对齐”翻译(即在数据库中创建记录或电子表格中的行)。每一组都应该包含M节,其中M是该节出现的翻译数,M< N.没有一首诗可能属于多个组。
到目前为止(使用各种可用于Python的API):
- 构建所有翻译中所有诗句的一维列表(跟踪哪一节来自哪个译本)
- 每一节:
- 用谷歌翻译把诗句翻译成英语
- 获得相对于所有其他经文的诗歌的tf-以色列国防军相似性
- 在其他翻译中找到最相似的诗句
实际上,我最终得到了一个有方向边的图。每个边都有一个可能性(百分比),它显示了它所指向的诗句与它所指的诗句的相似性。
示例:
- N=3个翻译
- 每翻译2节
- 正确的分组(就像人类将它们分组一样)是(A,B,C),(D,E,F)
- 我的算法给出:
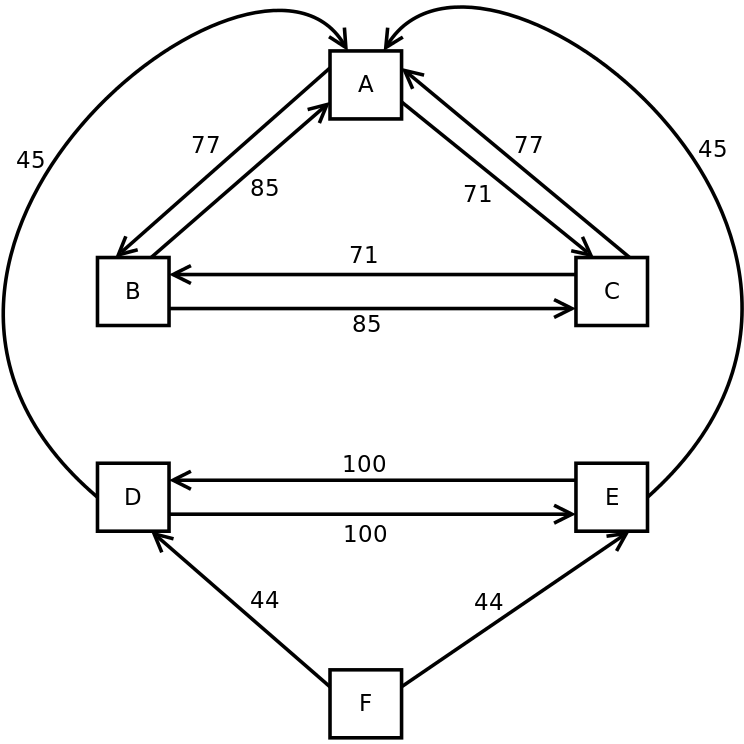
正确的分组在人眼看来是显而易见的。
如何扩展此算法以实现所需的分组?结果将由人类来检查,所以它不一定是完美的,但它必须是自动化的。
回答 2
Stack Overflow用户
发布于 2015-06-25 10:12:59
有些定义使解释更容易:
P(x,y) -从节点a到b的概率。(如上文- P(a,b)=77和P(b,a)=85 )。
CP(x,y) -组合概率。可以是P(x,y) * P(y,x)或P(x,y) + P(y,x)。
我建议的算法如下:
找到具有最高x, y的一对CP(x, y),然后将它们视为一个节点(a.k.a )。x_y)。重新计算图,以便考虑到两个节点中任何一个节点的每一个边。这是非常有效地使用图形的矩阵表示。
迭代此步骤,直到有M组为止。
Stack Overflow用户
发布于 2015-06-25 13:19:03
如果在注释中写入的诗句是按顺序排列的,那么这可以很容易地表述为编辑距离问题。
首先,假设您只有两种语言。您可以将您的问题重新表述如下:您需要使用以下操作将一个翻译(A)转换为另一个(B):您可以删除一节(这意味着这节在A中存在,但在B中不存在),您可以插入一节(它在A中不存在,但在B中存在),或者您可以用另一节替换一节(这意味着您匹配这两节)。您可以为这些操作中的每一个分配成本;替换成本将取决于您已经计算过的诗句相似性,并且您需要以某种方式定义插入或删除的成本(您可能需要在这方面进行实验)。在此之后,运行Wikipedia中提到的标准算法,然后在二次时间内得到匹配。
如果您有两种以上的语言,您可以使用类似的精确算法,但它会运行得更慢(O(N^k)和N开始最大的诗句数,k开始语言的数量),或者您可以使用一些近似的算法,比如首先匹配两种语言,然后添加第三种语言等等。
https://stackoverflow.com/questions/31045241
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号