
医学数据表转换为MySQL数据库设计
我正在尝试开发一个医疗症状检查应用程序,因此我需要将我的excel数据表转换成一个MySQL数据库,该数据表包含超过190 K的记录。我以前问过和阅读过多个相关的问题,但我仍然觉得很难创建一个高效/正确的数据库设计。
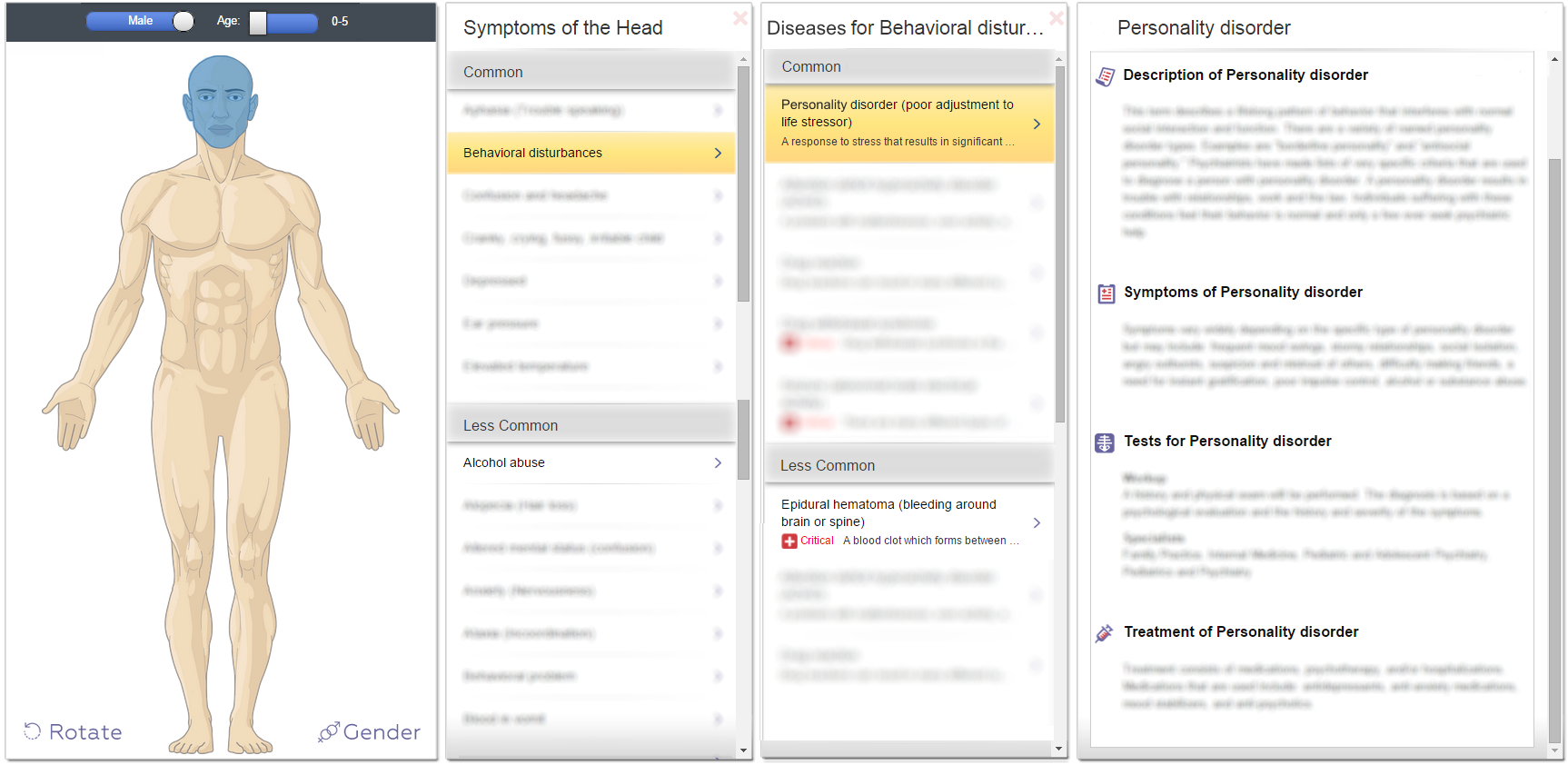
请看一下应用程序的设计(第一张图片),以了解应用程序是如何工作的。
步骤用户应遵循以检查症状
- 使用者选择性别、年龄和身体部位。
- App显示选定部位的所有(常见/不常见)症状。
- 使用者选择症状
- 应用程序询问是否有更多的症状适用(只有当症状有额外的症状在数据库中)。用户可以勾选2个额外的症状。
- App显示选择症状和附加症状的所有(常见/不常见)疾病。疾病的顺序(体重)取决于选定的年龄、性别、身体部位、主要症状和选定的附加症状。
- 使用者选择疾病
- App显示疾病信息
属性:age,gender,bodypart,symptom,disease
age:应用程序使用id查询数据库;0-5是1,6-17是2,18-59是3,60+是4gender:应用程序使用id查询数据库;男性为1,女性为0bodypart:应用程序使用id查询数据库;“头前面”是1,“颈前面”是2等等。symptom:名字,关键。创建关键信息是为了告诉用户,他/她需要立即与他们的医生联系。disease:名称,批判性,描述,测试和治疗。创建关键信息是为了告诉用户他/她需要立即联系他们的医生。
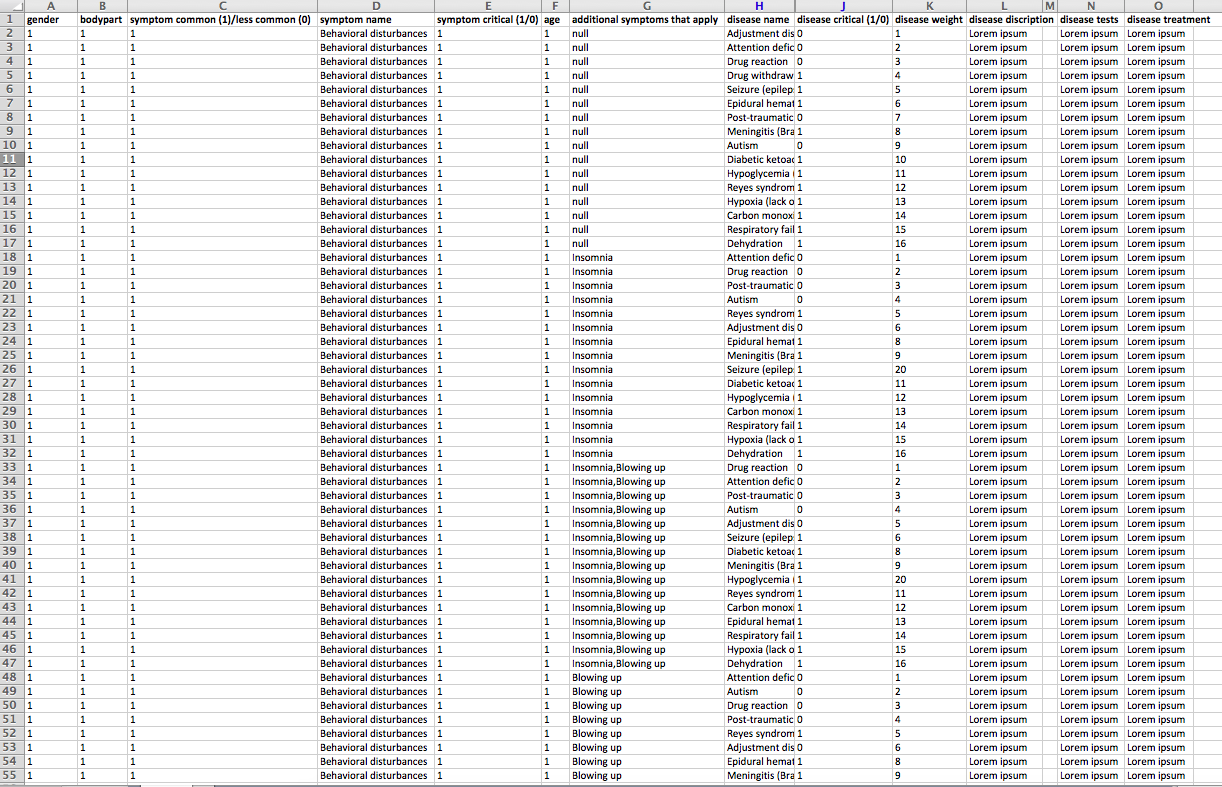
我已经有了一个包含所有数据和可能的输入/输出组合的数据库。不幸的是,它的设计并不适用于应用程序(第二张图片)。如第二张图片所示,疾病的顺序(疾病的重量)取决于选定的年龄、性别、身体部位、症状和其他症状(适用的附加症状)。每个症状可能有多达2个额外的症状。用户可以检查0,1或2的附加症状和疾病的顺序将是不同的每一个选项。
每种症状要么常见(1),要么不常见(0)。这取决于用户的输入(年龄、性别、身体部位)。
每种疾病体重<= 5被认为是一种常见病。体重>5的疾病被认为是较不常见的疾病。当然,这也取决于用户的输入(年龄、性别、身体部位、症状、附加症状)。我已经尝试了很多东西,但我仍然不知道如何设计这个功能,以适当的方式。
有人能帮我设计一个合适的数据库吗?
更新1
基本上,在设计数据库时,我们需要记住三个查询
- 获取所有的症状(symptom.id,symptom.name,symptom.critical,症状社区(常见/不常见)),属于选定的年龄= $age,性别= $gender和身体部分= $bp的组合。
- 获取所选症状的所有附加症状(symtpom.id symptom.name)
- 所有疾病(disease.id、disease.name、disease.critical病重)均属于年龄、性别、身体部位、主要症状和附加症状的组合。
应用程序设计
Excel数据表
回答 2
Stack Overflow用户
发布于 2015-06-21 22:19:37
Disease表相当简单;它包含列H..O,并删除重复项。另外,每一行都有一个唯一的ID。(参见AUTO_INCREMENT)我不清楚disease_weight是属于疾病表还是其他地方。
症状最好作为SET数据类型来实现。
另一个表包含性别、age_range、body_part、症状和disease_id (可能还有disease_weight)列。
我看到的主要SELECTs是
SELECT symptoms FROM table2
WHERE age_range = $ar
AND gender = $gender
AND body_part = $bp
AND FIND_IN_SET(symptoms, $symptom1);才能得到可能的次要症状。
(您还没有解释用户将如何输入age_range;我假设这将以$ar的形式出现在您的cgi语言中。(等)
SELECT d.name, ...
FROM Table2 t
JOIN Diseases d ON d.disease_id = t.disease_id
WHERE age_range ...
AND symptoms & $symptoms;(我可能对SET运算符有语法错误。)
如果还有其他的SELECTs,那么现在就需要考虑它们,而不是以后。
您尚未解释如何更新此数据集;这也可能是一个问题。
实际上,您并没有问如何从Excel获取到MySQL;让我们先完成数据库设计。
Stack Overflow用户
发布于 2017-02-02 10:48:41
我知道这个问题已经过时了。但是从我的研究来看,很多症状检测应用程序都在使用API来访问某些数据。来自这里,是使用的API之一。不确定是否使用您自己创建的数据库,但这是错误的做法,因为您使用的信息可能是错误的和过时的。
https://stackoverflow.com/questions/30969613
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号