
在texreg输出中包装自定义注释
我正试图在texreg创建的表的底部添加一个相当长的注释;我希望这只是简单的包装,但是函数中似乎没有内置的任何功能。
例如:
texreg(
lm(speed ~ dist, data = cars),
custom.note = paste(
"%stars. This regression should be",
"intepreted with strong caution as",
"it is likely plagued by extensive",
"omitted variable bias"
)
)在编译时,给出了如下内容:
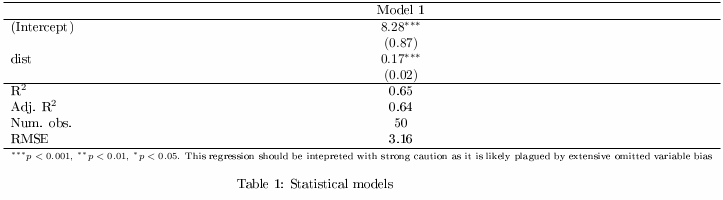
格式化非常糟糕;更好的方法是替换标准输出:
\multicolumn{2}{l}{\scriptsize{$^{***}p<0.001$, $^{**}p<0.01$, $^*p<0.05$. This regression should be intepreted with strong caution as it is likely plagued by extensive omitted variable bias}}用更易消化的包裹:
\multicolumn{2}{l}{\scriptsize{$^{***}p<0.001$, $^{**}p<0.01$, $^*p<0.05$.}} \\
\multicolumn{2}{l}{\scriptsize{This regression should be intepreted with}} \\
\multicolumn{2}{l}{\scriptsize{strong caution as it is likely plagued by}} \\
\multicolumn{2}{l}{\scriptsize{extensive omitted variable bias}}这使输出更接近我所要寻找的内容:

有什么办法可以用编程的方式来完成吗?
回答 3
Stack Overflow用户
发布于 2020-06-17 22:33:54
在1.37.1版(于2020年5月发布)中,texreg引入了threeparttable参数,它使用了为此目的而设计的threeparttable LaTeX包。
示例R代码:
texreg(lm(speed ~ dist, data = cars),
custom.note = paste("\\item %stars. This regression",
"should be interpreted with strong",
"caution as it is likely plagued by",
"extensive omitted variable bias."),
single.row = TRUE,
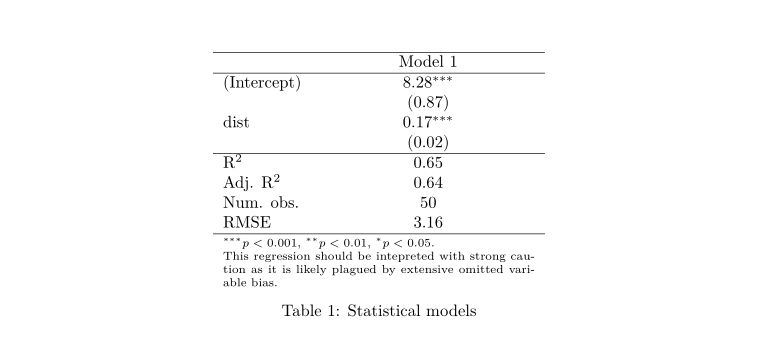
threeparttable = TRUE)输出:
\begin{table}
\begin{center}
\begin{threeparttable}
\begin{tabular}{l c}
\hline
& Model 1 \\
\hline
(Intercept) & $8.28 \; (0.87)^{***}$ \\
dist & $0.17 \; (0.02)^{***}$ \\
\hline
R$^2$ & $0.65$ \\
Adj. R$^2$ & $0.64$ \\
Num. obs. & $50$ \\
\hline
\end{tabular}
\begin{tablenotes}[flushleft]
\scriptsize{\item $^{***}p<0.001$; $^{**}p<0.01$; $^{*}p<0.05$. This regression should be interpreted with strong caution as it is likely plagued by extensive omitted variable bias}
\end{tablenotes}
\end{threeparttable}
\caption{Statistical models}
\label{table:coefficients}
\end{center}
\end{table}它被呈现为:

请注意,自定义注释必须以\\item开头。也可以有多个项目和/或使用项目点来格式化多个注释,如列表中的:
texreg(lm(speed ~ dist, data = cars),
custom.note = paste("\\item[$\\bullet$] %stars.",
"\\item[$\\bullet$] This regression",
"should be interpreted with strong",
"caution as it is likely plagued by",
"extensive omitted variable bias."),
single.row = TRUE,
threeparttable = TRUE)格式并不完美,因为您无法设置表的所需宽度;注释只是根据相应表的宽度进行调整。但我认为,在实际使用场景中,一次显示多个模型,一些系数名称比示例中的要长,这应该不是什么问题。此解决方案还支持longtable环境,在这种情况下,将使用threeparttablex包。
下面是一个例子,说明如何用两个模型使它看起来很漂亮:
fit <- lm(speed ~ dist, data = cars)
texreg(list(fit, fit),
custom.note = paste("\\item[\\hspace{-5mm}] %stars.",
"\\item[\\hspace{-5mm}] This regression",
"should be interpreted with strong",
"caution as it is likely plagued by",
"extensive omitted variable bias."),
single.row = TRUE,
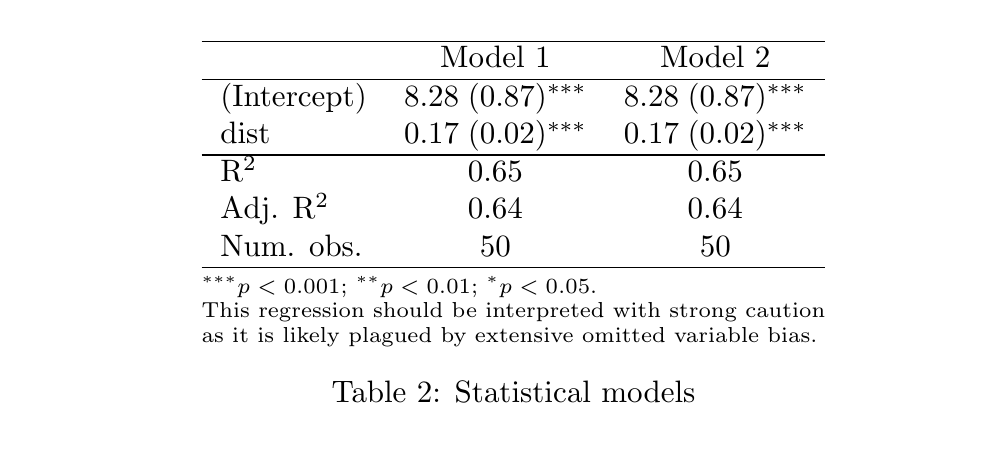
threeparttable = TRUE)这产生了:
\begin{table}
\begin{center}
\begin{threeparttable}
\begin{tabular}{l c c}
\hline
& Model 1 & Model 2 \\
\hline
(Intercept) & $8.28 \; (0.87)^{***}$ & $8.28 \; (0.87)^{***}$ \\
dist & $0.17 \; (0.02)^{***}$ & $0.17 \; (0.02)^{***}$ \\
\hline
R$^2$ & $0.65$ & $0.65$ \\
Adj. R$^2$ & $0.64$ & $0.64$ \\
Num. obs. & $50$ & $50$ \\
\hline
\end{tabular}
\begin{tablenotes}[flushleft]
\scriptsize{\item[\hspace{-5mm}] $^{***}p<0.001$; $^{**}p<0.01$; $^{*}p<0.05$. \item[\hspace{-5mm}] This regression should be interpreted with strong caution as it is likely plagued by extensive omitted variable bias.}
\end{tablenotes}
\end{threeparttable}
\caption{Statistical models}
\label{table:coefficients}
\end{center}
\end{table}它呈现为:
Stack Overflow用户
发布于 2017-06-28 08:55:00
我可能会指出一个整洁的alternative solution I received,这可能是您感兴趣的,最晚时,您需要更新的文本包。
因此,自定义注释在\multicolumn代码中以LaTeX结尾,因此我们不能使用诸如par或\\之类的中断行命令。但是我们可以用\parbox实现自动断线。如果我们仍然想要一个自定义行中断,我们可以使用四个反斜杠\\\\。为了更好地格式化,我们可以在文本内容的开头使用\\vspace{2pt}:
texreg(lm(speed ~ dist, data = cars),
custom.note = ("\\parbox{.4\\linewidth}{\\vspace{2pt}%stars. \\\\
This regression should be intepreted with strong caution as it is
likely plagued by extensive omitted variable bias.}"))
Stack Overflow用户
发布于 2015-06-17 22:37:07
到目前为止,我已经想出了一个解决办法,通过添加一个texreg参数并进行更改来重写custom.note.wrap函数:
note <- paste0("\\multicolumn{", length(models) + 1,
"}{l}{\\", notesize, "{", custom.note, "}}")
note <- gsub("%stars", snote, note, perl = TRUE)至:
if (custom.note.wrap){
note<-paste(paste0("\\multicolumn{", length(models) + 1L,"}{l}{\\",notesize,"{",
strwrap(custom.note, width=custom.note.wrap), "}}"),
collapse = " \\ \n")
note <- gsub("%stars", snote, note, perl = TRUE)
}else{
note <- paste0("\\multicolumn{", length(models) + 1L,
"}{l}{\\", notesize, "{", custom.note, "}}")
note <- gsub("%stars", snote, note, perl = TRUE)
}这样做的目的是为每一行(custom.note.wrap)选择一个最大字符串长度,然后将所提供的便笺拆分为最多以空格结尾的字符串,最后将所有内容连接到一串带有每个拆分子字符串的multicolumn。
这不是最优的,因为texreg (有能力)在给定模型名称的长度等情况下自动设置custom.note.wrap会更好。但是我缺乏原始的LaTeX能力,所以我不确定如何做到这一点。
https://stackoverflow.com/questions/30902906
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号