
如何根据“突发”对图像进行分组?
我想这需要一些解释,所以请容忍我.
我一次用4-6的子秒脉冲捕获了2000+图像.它们都被扔在同一个地方,所以我得把它们分类。我需要按脉冲排列它们,但是EXIF数据只能提供一分钟的分辨率。爆发应该是几乎完全相同的事情,不同的爆发被设计成明显不同。
我需要查看每一张图片,并将其与下面的图片进行比较,看看是否相似。如果它太不一样了,它必须是来自另一个突发,它需要进入一个新的文件夹,以及以下任何类似它的图像,以此类推。
我的想法是将当前图像的每个像素与下一个像素之间的差值的绝对值相加。一旦这个和达到了一个阈值,那么这一定意味着它们来自不同的爆发(我可以做一些测试来找出一个好的阈值是什么)。
最大的问题是怎么做?PIL/枕头支持这样的东西吗?是否有更好的方法来判断一幅图像是否与另一幅图像“大部分”相同?
与使用任何特定技术相比,我更感兴趣的是快速地对它们进行排序,因此欢迎使用其他方法。
...and几乎必须是Python。
编辑:下面是两个应该放在同一个文件夹中的示例图像:


这些是来自以下突发的两个图像,应该放在另一个文件夹中:


回答 4
Stack Overflow用户
发布于 2015-06-17 02:36:44
抱歉,原来EXIF数据是可行的。看起来有一个很好的10-15秒之间的爆发,所以它应该是非常容易判断何时结束和另一个开始。
PIL/Pillow有足够的工具,可以使用以下方法查看创建日期:
from PIL.ExifTags import TAGS
def get_exif(fn):
ret = {}
i = Image.open(fn)
info = i._getexif()
for tag, value in info.items():
decoded = TAGS.get(tag, tag)
ret[decoded] = value
return ret沿着这条线...or一些东西。
Stack Overflow用户
发布于 2015-06-17 01:20:39
如果您想要进行基于内容的匹配,而不是上面的好人建议的基于时间戳的排序,那么OpenCV库是一个很好的选择。查看这篇文章,了解如何使用OpenCV库进行图像相似性匹配的不同技术:Checking images for similarity with OpenCV
关于同一个话题有很多这样的问题,所以仔细阅读会给你一个更好的想法。
根据上面的时间观念,当我只画出你的照片拍摄的时间时,这就是我得到的一个情节:
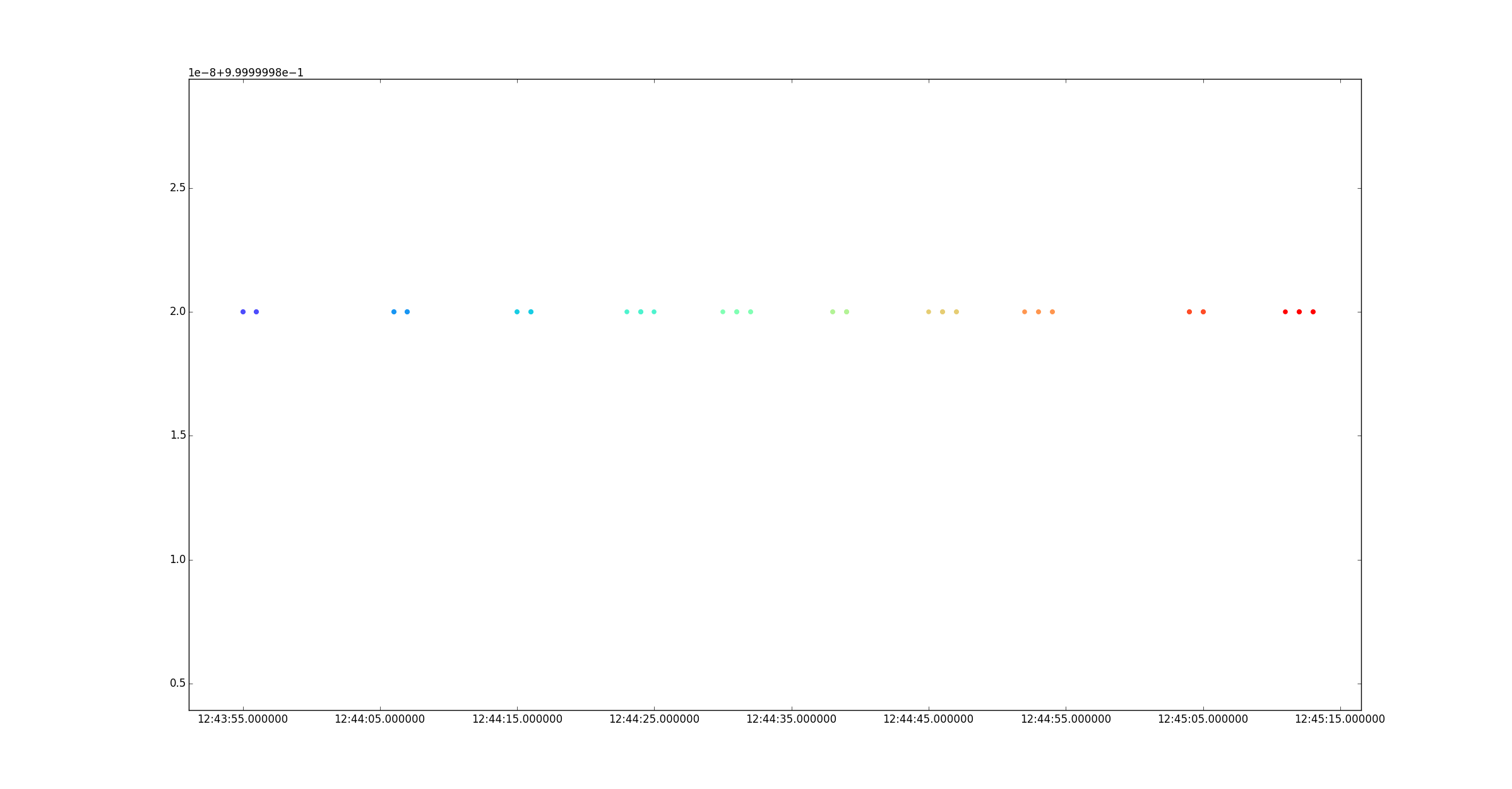
不同的颜色代表不同的文件夹(应该使用不同的颜色地图来提高可见度,但是哦……)。
仅仅基于这些时间,它确实看起来像你的簇间时间,明显比你的簇内时间更明显。
我还在下面的输出中计算了一些集群内和簇间指标:
folder: ImageBurstsDataset/001
Total image files in folder: 6
Total intra-cluster time: 1.0
Average intra-cluster time: 0.166666666667
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/002
Total image files in folder: 7
Total intra-cluster time: 1.0
Average intra-cluster time: 0.142857142857
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/003
Total image files in folder: 6
Total intra-cluster time: 1.0
Average intra-cluster time: 0.166666666667
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/004
Total image files in folder: 6
Total intra-cluster time: 2.0
Average intra-cluster time: 0.333333333333
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/005
Total image files in folder: 6
Total intra-cluster time: 2.0
Average intra-cluster time: 0.333333333333
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/006
Total image files in folder: 6
Total intra-cluster time: 1.0
Average intra-cluster time: 0.166666666667
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/007
Total image files in folder: 6
Total intra-cluster time: 2.0
Average intra-cluster time: 0.333333333333
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/008
Total image files in folder: 5
Total intra-cluster time: 2.0
Average intra-cluster time: 0.4
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/009
Total image files in folder: 6
Total intra-cluster time: 1.0
Average intra-cluster time: 0.166666666667
Max: 1.0, Min: 0.0
folder: ImageBurstsDataset/010
Total image files in folder: 6
Total intra-cluster time: 2.0
Average intra-cluster time: 0.333333333333
Max: 1.0, Min: 0.0
Inter-cluster times: [10.0, 8.0, 7.0, 5.0, 6.0, 6.0, 5.0, 10.0, 6.0]免责声明:仓促地编写这个脚本,只需要返回并确保所有的边缘案例都是正确的。但否则..。我从您上传的数据集中得出的结论是:
- 在集群中,一张图片与前一张图片相距不超过1秒。
- 下一个集群中的第一个图片与前一个集群中的最后一个图片至少相隔5秒。
Stack Overflow用户
发布于 2015-06-17 01:26:15
两幅图像有多相似是一个开放的研究问题。然而,考虑到您的图像是在一个快速爆炸,使用绝对差异是合理的。另一种可能性是使用相关性,例如,倍增像素值并接受高于阈值的结果。
问题是速度问题。根据您对准确性的要求,您可能能够对图像进行相当大的子采样。也许比较100个或1000个均匀分布像素的值--每幅图像中相同的像素--会给你一个足够准确的统计数据。
https://stackoverflow.com/questions/30880804
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号