
在Apache的RDDs中,血统是如何传承的?
每个RDD都指向相同的沿袭图吗?
或
当父RDD将其谱系分配给新的RDD时,也是子RDD复制的谱系图,因此父图和子图都有不同的图。在这种情况下,它不是内存密集型的吗?
回答 2
Stack Overflow用户
发布于 2015-06-08 04:35:33
每个RDD维护一个指向一个或多个父节点的指针,以及关于它与父类之间的关系类型的元数据。例如,当我们在RDD上调用b a**,时,RDD 只保留对父val b = a.map()的引用(而不是复制),这是一个沿袭**。
当驱动程序提交作业时,RDD图被序列化到工作者节点,以便每个工作节点应用一系列转换(例如,映射筛选器等等)。在不同的分区上。此外,如果发生故障,将使用这个RDD谱系来重新计算数据。
为了显示RDD的谱系,Spark提供了一个调试方法toDebugString()方法。
请考虑以下示例:
val input = sc.textFile("log.txt")
val splitedLines = input.map(line => line.split(" "))
.map(words => (words(0), 1))
.reduceByKey{(a,b) => a + b}在toDebugString()上执行splitedLines RDD,将输出以下内容
(2) ShuffledRDD[6] at reduceByKey at <console>:25 []
+-(2) MapPartitionsRDD[5] at map at <console>:24 []
| MapPartitionsRDD[4] at map at <console>:23 []
| log.txt MapPartitionsRDD[1] at textFile at <console>:21 []
| log.txt HadoopRDD[0] at textFile at <console>:21 []有关星火如何内部工作的更多信息,请阅读my another post
Stack Overflow用户
发布于 2017-12-07 11:21:17
当调用转换(map或filter等)时,星火不会立即执行它,而是为每个转换创建一个沿袭。谱系将跟踪应用于该RDD的所有转换,包括它必须读取数据的位置。
例如,请考虑以下示例
val myRdd = sc.textFile("spam.txt")
val filteredRdd = myRdd.filter(line => line.contains("wonder"))
filteredRdd.count()sc.textFile()和myRdd.filter()不能立即执行,只有在RDD上调用了filteredRdd.count()时才会执行。
操作用于将结果保存到某个位置或显示结果。还可以使用命令filteredRdd.toDebugString(filteredRdd是这里的RDD )来打印RDD沿袭信息。此外,DAG可视化以非常直观的方式显示了完整的图形,如下所示:
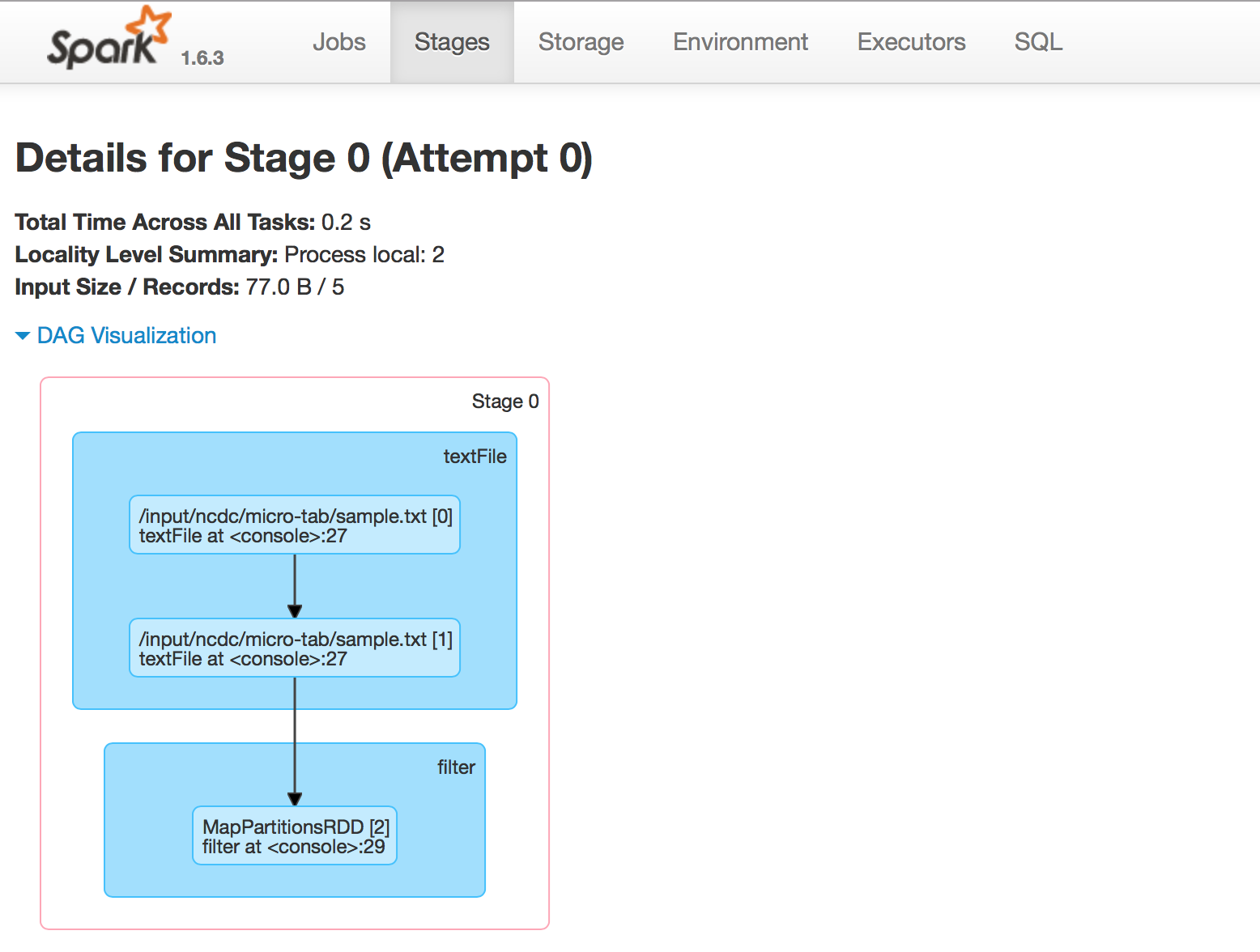
https://stackoverflow.com/questions/30699530
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号