
Knuth-Morris-Pratt算法中的DFA构造
我指的是Sedgewick的书“算法”(第4版)中用于子字符串搜索的Knuth Pratt (KMP)算法的大纲。
KMP算法在基于确定性有限自动机(DFA)的子串搜索中使用备份。我理解DFA是如何进入算法的,但是我不知道如何构造DFA,这是由以下代码片段完成的:
dfa[pat.charAt(0)][0] = 1;
for (int X = 0; j = 1; j< M; j++) {
for (int c = 0; c < R; c++) {
dfa[c][j] = dfa[c][X];
}
dfa[pat.charAt(j)][j] = j+1;
X = dfa[pat.charAt(j)][X];
}其中M是模式的长度,pat和R是字母表的大小。charAt()函数在相应的位置返回字符的整数值。
有人能解释这段代码是以什么方式构造dfa的吗?我迷失了内在循环的实际直觉意义。
回答 1
Stack Overflow用户
发布于 2015-05-30 16:15:53
让我们看一看下面的FA模式ACACAGA。
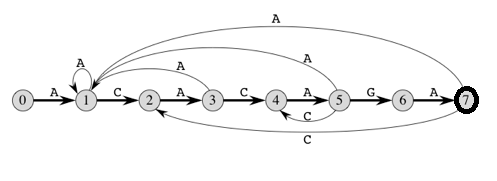
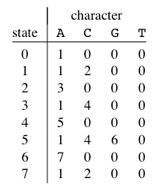
上面的图表表示模式ACACAGA的图形表示和表格表示。
这里,DFA中的状态数是M+1,其中M是模式的长度。构建DFA的主要工作是为每个可能的字符从当前状态获取下一个状态。给定一个字符x和状态k,我们可以考虑字符串“pat0..k-1x”,它基本上是模式字符pat,pat1…的连接,从而得到下一个状态。这个概念是得到给定模式最长前缀的长度,这样前缀也是“pat0..k-1x”的后缀(LPS)。长度的值给出了下一个状态。
{kind=link}
例如,让我们看看如何从当前状态5和上面图表中的字符‘C’获得下一个状态。我们需要考虑字符串“pat0.5c”,即“ACACAC”。该模式最长的前缀长度为4(“ACAC”),前缀为“ACAC”的后缀。因此,下一个状态(来自状态5)是字符‘C’的4。
// dfa[i][j] = k denotes the transition function will go k'th state
// with character i from state j
// DFA will go always (i + 1)'th state from i'th state
//if the character c is equal to current character of pattern
dfa[pat.charAt(0)][0] = 1;
// here X is initialized with LPS (longest prefix suffix)
// of pattern[0....j - 1]. LPS[0] is always 0
for (int X = 0; j = 1; j< M; j++) {
for (int c = 0; c < R; c++) { // for all possible characters
// transition function from j'th state taking character c
// will go to the same state where it went from X(LPS)'th state
// taking character c (justify it with an example)
dfa[c][j] = dfa[c][X];
}
// DFA will go always (i + 1)th state from i'th state if
// the character c is equal to current character of pattern
dfa[pat.charAt(j)][j] = j + 1;
X = dfa[pat.charAt(j)][X]; // update LPS
}https://stackoverflow.com/questions/30548170
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号