
在ANTLR4中识别节点深度为文本的树
我试图解析一些描述树的输入文本。
为了更好地解释这个问题,我不是从文本开始,而是从预期的结果开始:
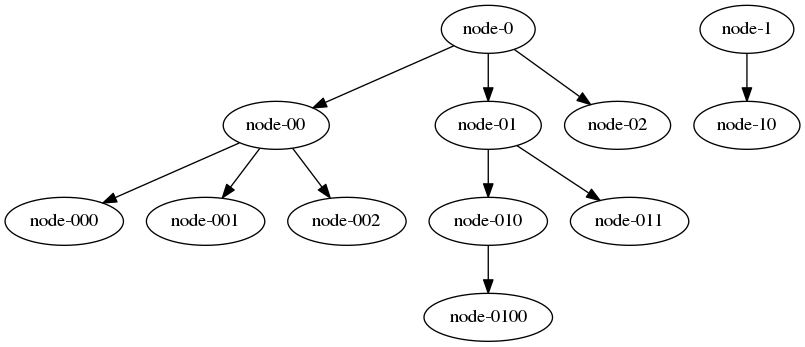
这个树可以写成带括号的表达式(例如):
node-0 (node-00 (node-000 node-001 node-002) node-01 (node-010 (node-0100) node-011) node-02)
node-1 (node-10)使用ANTLR4识别非常简单:
grammar ParenthesizedDepthGrammar;
WS : (' '|'\n') -> channel(HIDDEN);
TEXT : [-A-Za-z0-9]+;
root: item*;
item:
TEXT ('(' item+ ')')?
;现在的问题是,我的输入描述了树,而不是一个带括号的表达式。相反,每个节点都得到一个数字,该数字表示其深度,并且它隐式地属于最近的前一个节点,其深度较浅。如下所示:
1 node-0
2 node-00
3 node-000
3 node-001
3 node-002
2 node-01
3 node-010
4 node-0100
3 node-011
2 node-02
1 node-1
2 node-10我认为以下语法会正确地识别它:
grammar TextualDepthGrammar;
WS : (' '|'\n') -> channel(HIDDEN);
LEVEL : [0-9]+;
TEXT : [-A-Za-z0-9]+;
root: item[0]*;
item[int parentLevel] returns [int level]:
LEVEL
{ $level = $LEVEL.int; }
{ $level > $parentLevel }?
TEXT
item[$level]*
;但事实并非如此。
语义谓词{ $level > $parentLevel }?正确地削减了解析,但是LEVEL已经被消耗,而祖父母树节点没有机会尝试解析新的子节点。
我认为它要么需要:
- 若要将lexer倒带到“取消消费”
LEVEL;或 LEVEL在item规则的最开始,如果它不比父规则更深的话,就放弃它。
但是怎么做?
回答 2
Stack Overflow用户
发布于 2015-05-29 16:33:00
我可以使用getCurrentToken()查看(readahead)下一个令牌来解决这个问题:
grammar TextualDepthGrammar;
WS : (' '|'\n') -> channel(HIDDEN);
LEVEL : [0-9]+;
TEXT : [-A-Za-z0-9]+;
root: item*;
item:
LEVEL
TEXT
(
{ Integer.parseInt(getCurrentToken().getText()) > $LEVEL.int }?
item
)*
;供投入:
1 node-0
2 node-00
3 node-000
3 node-001
3 node-002
2 node-01
3 node-010
4 node-0100
3 node-011
2 node-02
1 node-1
2 node-10它正确地指出:
(root
(item 1 node-0
(item 2 node-00
(item 3 node-000)
(item 3 node-001)
(item 3 node-002)
)
(item 2 node-01
(item 3 node-010
(item 4 node-0100)
)
(item 3 node-011)
)
(item 2 node-02)
)
(item 1 node-1
(item 2 node-10)
)
)不过,我觉得使用getCurrentToken() 有点麻烦.
,如果该决定取决于进一步的令牌,怎么办?
如果有从当前令牌到令牌的可选令牌(如果要做出决定),那么怎么办?
Stack Overflow用户
发布于 2015-05-29 22:50:35
确保您已经修复了所有语法生成错误和警告,或者确定它们是无关紧要的。TEXT规则应该给出一个不完整的范围警告。若要在集合中包含文字连字符,它必须是最后一个元素。
TEXT : [A-Za-z0-9-]+;为了确保解析器考虑所有输入,您需要肯定地匹配EOF令牌。
root: item* EOF;按照Antlr的工作方式,在计算第一个解析器规则之前,lexer将使用所有的输入。对于解析器来说,没有一种简单的(或有意的)方法来控制lexer的操作。
做你想做的事情的惯用方法是解析和生成整个输入文本的树。然后,在树遍历器中,可以分析受任意一组选定约束约束的树。多个步行器可以用于不同的约束集,所有这些都不需要树的再生。
https://stackoverflow.com/questions/30530453
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号