
脑电时间序列自回归模型的拟合
因此,我认为可以将AR模型与EEG数据进行拟合,然后利用AR系数作为特征进行聚类或分类:例如Mohammadi等人的识别,利用AR模型对EEG信号进行识别,2006年。
作为质量控制步骤,并作为解释的帮助,我想要直观地看到由拟合模型产生/模拟的时间序列的类型。这也将允许我展示原型模型,如果我是做K的手段或什么分类。
然而,我似乎所能产生的只是噪音!
任何朝着我想要的方向迈进的步骤都将是非常受欢迎的。
section1 = data[88000:91800]
section2 = data[0:8000]
section3 = data[143500:166000]
section1 -= np.mean(section1)
section2 -= np.mean(section2)
section3 -= np.mean(section3)密谋时:
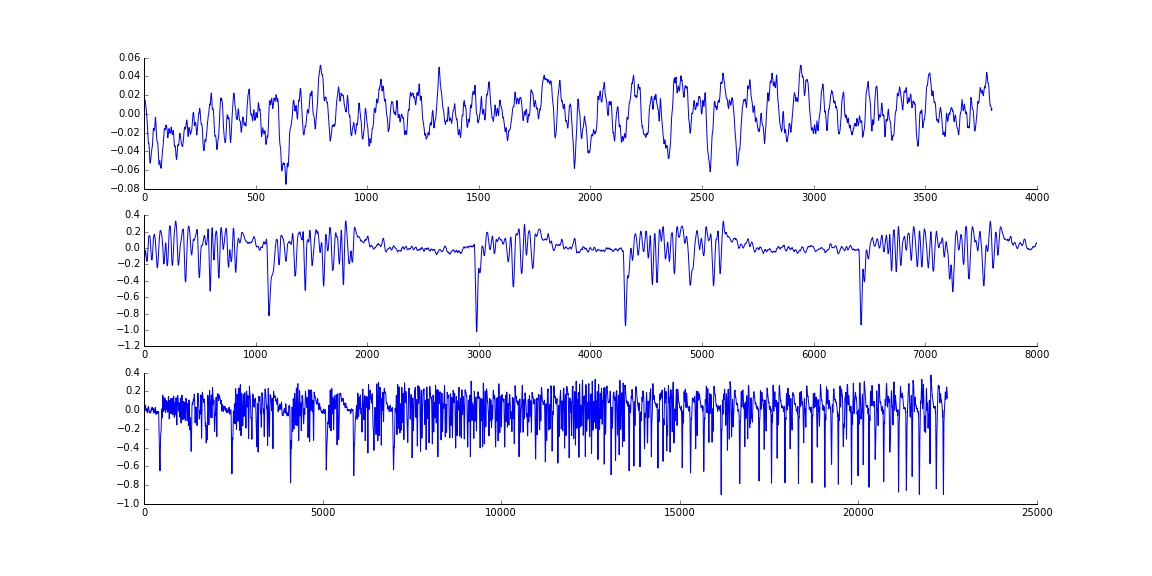
maxOrder = 20
model_one = AR(section1).fit(maxOrder, ic = 'aic', trend = 'nc')
model_two = AR(section2).fit(maxOrder, ic = 'aic', trend = 'nc')
model_three = AR(section3).fit(maxOrder, ic = 'aic', trend = 'nc')
fake1 = arma_generate_sample(model_one.params,[1],1000, sigma = 1)
fake2 = arma_generate_sample(model_two.params,[1],1000,sigma = 1)
fake3 = arma_generate_sample(model_three.params,[1],1000,sigma = 1)
ax1.plot(fake1)
ax2.plot(fake2)
ax3.plot(fake3)
回答 1
Stack Overflow用户
发布于 2015-05-27 23:58:30
关于脑电图数据,最简单的说法是它有1/f或“粉红色”分布,这是最简单的说法。1/f信号的一个有趣之处在于它们是非平稳的,不能被任何阶的ARMA过程正确地建模。(1/f意味着低频波动是任意大的,这意味着任意距离的点仍然是相关的,而且你拥有的数据越多,你所能检测到的相关性就越远-- ACF永远不会收敛到任何有限的东西。另外,重要的是要认识到光谱含量和类ARMA过程是超级相关的,因为信号的自相关函数完全决定了它的光谱分布,反之亦然--这两个函数是相互之间的傅里叶变换。
因此,这基本上意味着,你使用基本时间序列统计数据所做的任何事情都将是一个巨大的理论--违反了黑客行为。这并不意味着它不会在实践中产生一些有用的分类特征,但校准您的期望相应.很可能你得到的结果和Mohammadi等人得到的结果完全一样,他们只是没有费心去检查/报告是否合适。
通过小波或ARIMA过程,可以直接对1/f噪声进行建模。
根据您的数据,您可能还需要担心偏离简单1/f分布的情况:诸如alpha (在10 Hz的频谱分布中产生很大的起伏)、像肌肉噪声、电线噪声和心跳(这也会导致与简单的1/f谱有很大的偏差--特别是肌肉会产生非常独特的宽带~白色噪声),以及眨眼(这会产生巨大的脉冲偏差,而这种偏差不会被任何假设平稳或在频率域中工作的技术所模拟)。
在我的论文的5.3节中有更多关于这些问题的讨论(参考资料),尽管是在进行类似ERP的分析而不是机器学习的背景下。
https://stackoverflow.com/questions/30488890
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号