
Python与Scala (用于火花作业)
我是很新的火花,目前探索它通过玩火和火花壳。
所以情况是这样的,我用火花放电和火花壳运行同样的火花作业。
这是火花放电的结果:
textfile = sc.textFile('/var/log_samples/mini_log_2')
textfile.count()这个是火花壳的:
textfile = sc.textFile("file:///var/log_samples/mini_log_2")
textfile.count()我两次都试了几次,第一次(python)一次需要30-35秒才能完成,第二次(scala)大约需要15秒。我很好奇是什么导致了这种不同的性能结果?是因为语言的选择或者火花壳在背景中做了一些不需要的事情吗?
更新
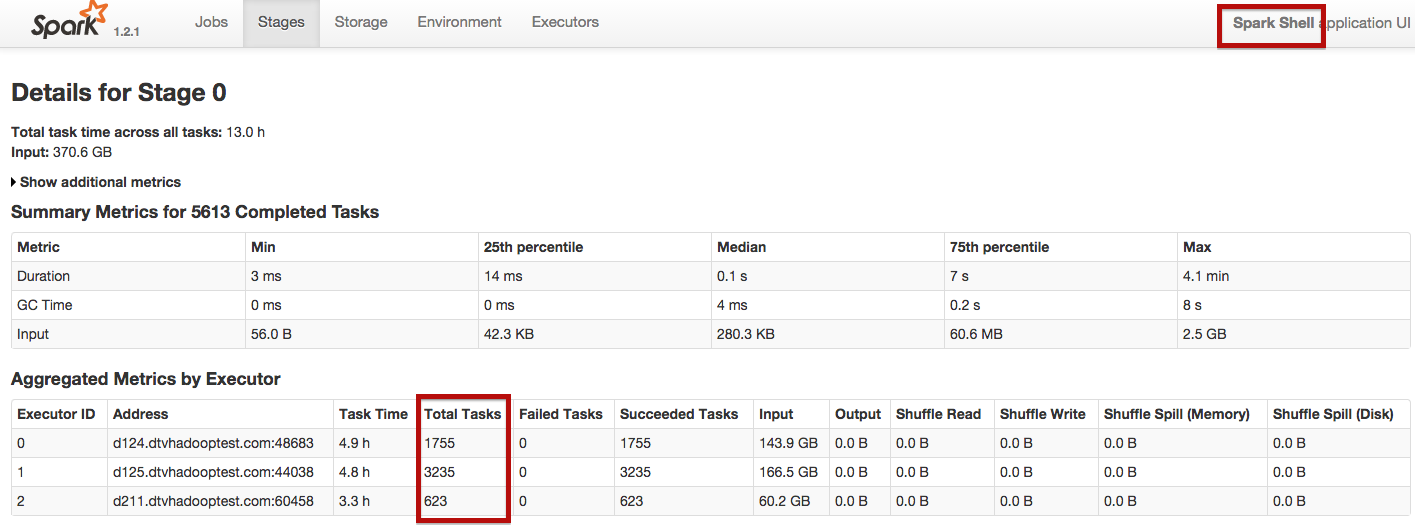
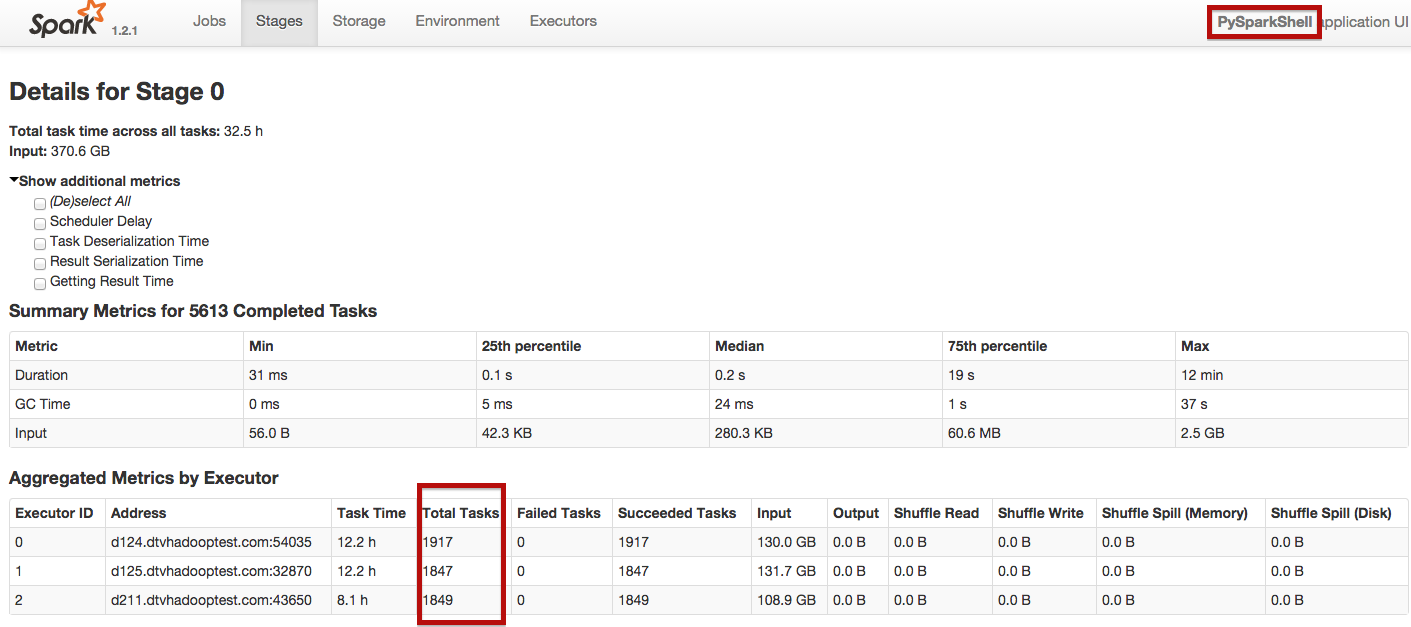
所以我在更大的数据集上做了一些测试,总共大约550 GB (压缩)。我正在使用火花独立作为大师。
我观察到,在使用火花放电时,任务在执行者之间是平等的。然而,当使用火花壳时,任务并不是平等共享的。功能越强的机器得到的任务越多,而较弱的机器得到的任务就越少。
有了火花壳,工作在25分钟内完成,而火花放电则在55分钟左右完成.我如何使火花独立分配任务与火星雨,因为它分配任务与火花壳?
回答 1
Stack Overflow用户
发布于 2015-05-27 09:49:18
使用python有一定的开销,但它的重要性取决于您正在做什么。尽管最近的报告显示开销并不大(特别针对新的DataFrame API)
您所遇到的一些开销与每个作业开销的常数有关--这几乎与大型作业无关。您应该使用更大的数据集来做一个示例基准测试,看看开销是一个常量加法,还是与数据大小成正比。
另一个潜在的瓶颈是为每个元素(map等)应用python函数的操作--如果这些操作与您相关,您也应该对它们进行测试。
https://stackoverflow.com/questions/30477982
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号