
如何从Apache中的Twitter Tweets中提取hashtag(或其他数组)
我试图从JSON对象文件中使用Apache对Twitter Tweet数据进行分析。
下面是我如何使用Spark的jsonFile方法加载它:
val sqc = new org.apache.spark.sql.SQLContext(sc)
val tweets = sqc.jsonFile("stored_tweets/*.json")
tweets.registerTempTable("tweets")接下来,我只使用以下行对hashtag实体进行了示例:
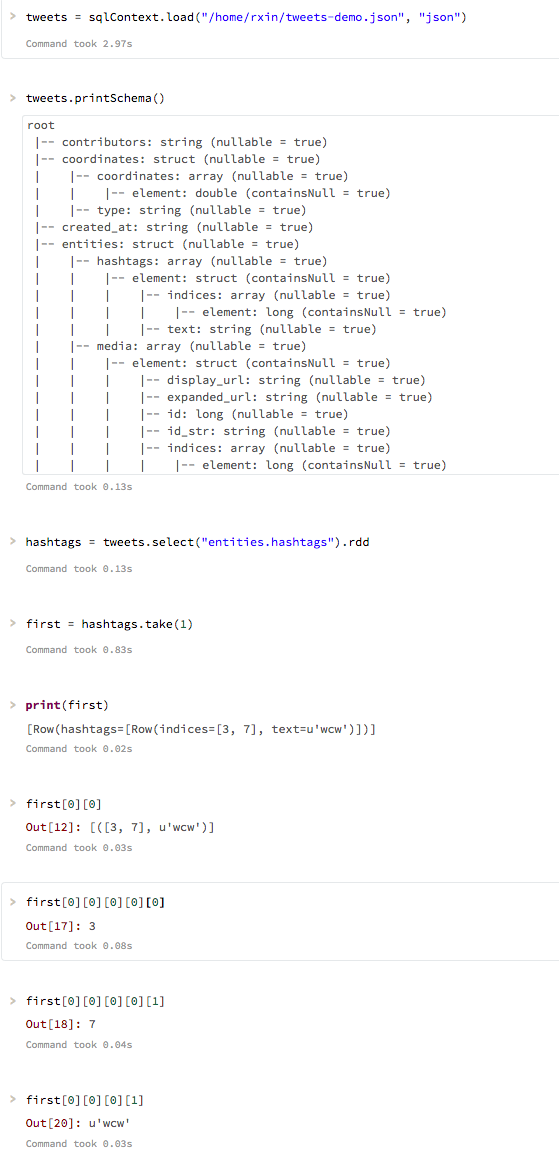
val hashtags = sqc.sql("SELECT entities.hashtags FROM tweets LIMIT 3")
hashtags.take(1) 结果是:
res14: Arrayorg.apache.spark.sql.Row =Array([ArrayBuffer(ArrayBuffer,43,50),在线,ArrayBuffer(51,61),市场营销,ArrayBuffer(88,102),增长黑客,ArrayBuffer(103,111),入站,ArrayBuffer(112,120),创业,ArrayBuffer(121,138),内容营销)])
如果您仔细观察,数据就在那里,但是它被包装在数组([ArrayBuffer(xx,yy),hashtag)中。
有些人建议使用.map()或.flatMap(),并使用或不使用自定义函数,使用.getAs()方法,但我不明白这是如何工作的。
有什么想法吗?
更新5月23日:
一直在查看星火博士。还是没有进展。Spark文档(https://spark.apache.org/docs/1.0.1/api/java/org/apache/spark/sql/api/java/Row.html)建议使用如下代码
import org.apache.spark.sql._
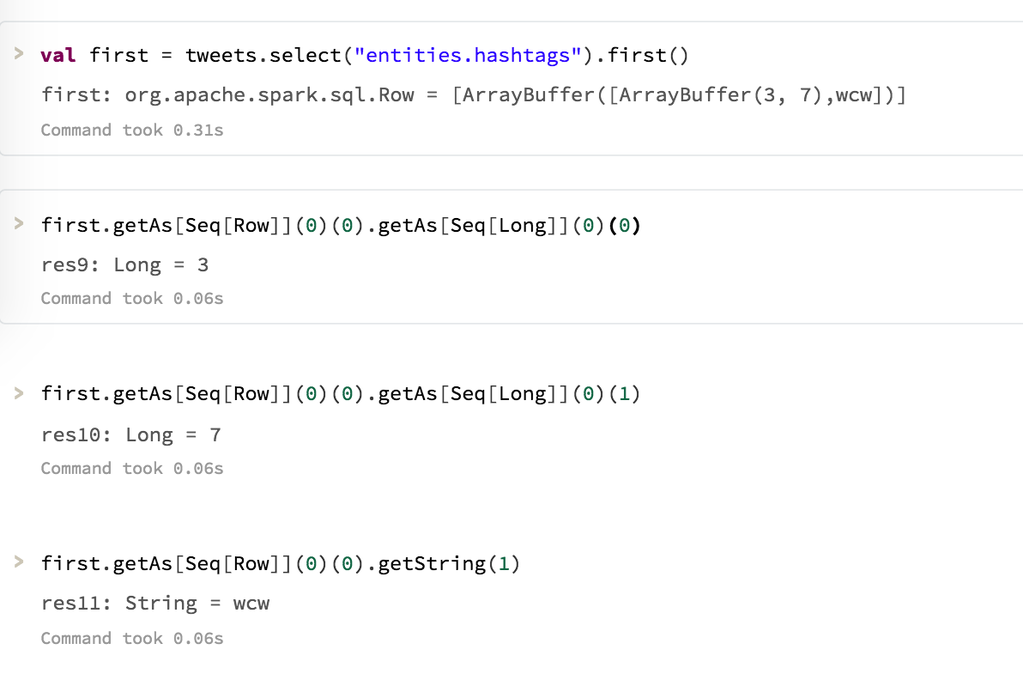
val row = hashtags.take(1)
row(0)然而,在这种情况下,这会产生
res124: org.apache.spark.sql.Row =[ArrayBuffer(ArrayBuffer,43,50),在线,ArrayBuffer(51,61),市场营销,ArrayBuffer(88,102),增长黑客,ArrayBuffer(103,111),入站,ArrayBuffer(112,120),创业,ArrayBuffer(121,138),内容营销)]
在这里,这个StackOverflow post (org.apache.spark.sql.Row to Int)建议使用.get()系列的方法,比如StackOverflow,但是我的尝试并没有产生太多的结果:
row(0).getString(0)产量:
java.lang.ClassCastException:不能将scala.collection.mutable.ArrayBuffer转换为java.lang.String
和,
row(0).getString(1)产量:
28:错误:值getString不是任何行(0).getString(1)的成员
和
row(0)(0)产量
res184: Any = ArrayBuffer(ArrayBuffer(43,50),在线,ArrayBuffer(51,61),市场营销,ArrayBuffer(88,102),增长黑客,ArrayBuffer(103,111),入站,ArrayBuffer(112,120),创业,ArrayBuffer(121,138),内容营销)
但是后来
row(0)(0)(0)产量
:28: error: Any不接受参数行(0)(0)(0)
所以还是被困住了。
更新5月24日:
在尝试使用.textFile() (非Spark方式)和使用本机Scala解析功能(按照这里的指示:Spark SQL - How to select on dates stored as UTC millis from the epoch? )和解决这里描述的火花json4s兼容性问题:https://github.com/json4s/json4s/issues/212之后,我决定尝试使用Python,如果这样可以解决这些问题。
更新2,5月24日:
在一位朋友的帮助下,他建议尝试这样的方法:
import scala.collection.mutable.ArrayBuffer
row(0)(0).asInstanceOf[ArrayBuffer[Any]](0).asInstanceOf[ArrayBuffer[Any, String]]我终于找到了一些进展,因为这起作用了:
row(0)(0).asInstanceOf[ArrayBuffer[Any]](0)并制作:
res53: Any = ArrayBuffer(43,50),在线
但是,在按建议进行时:
val a = row(0)(0).asInstanceOf[ArrayBuffer[Any]](0)
a.asInstanceOf[ArrayBuffer[Any, String]]其结果令人沮丧:
22:错误: scala.collection.mutable.ArrayBuffer类型参数的错误数目,应该是1 a.asInstanceOf[ArrayBufferAny,String]
试着这样:
a.asInstanceOf[ArrayBuffer[Any]]产量:
org.apache.spark.sql.catalyst.expressions.GenericRow不能转换为scala.collection.mutable.ArrayBuffer
又卡住了。
更新3,5月24日:
所以,在得到一个朋友的帮助后,我得到了两种可能的解决方案,这两种方法都不是对最初问题的直接回答,而是“某种程度上”解决问题。
选项1 (与一起使用的简单选项):使用pyspark -您只需说:
row[0][0][1]选项2 (Scala中丑陋的解决方案):
val solution = row(0)(0).asInstanceOf[ArrayBuffer[Any]](0).toString().split(" ")(1).split(",")(1).split("]")(0)产生的结果:
scala>解决方案res28: String = online
我不得不使用.asInstanceOf()而不是toString()的原因是,最终的对象包装是:
Any = ArrayBuffer(43,50),在线
..and,我们找不到一个.asInstanceOf() -approach。我们尝试过的事情如下:
row(0)(0).asInstanceOf[ArrayBuffer[Any]](0).asInstanceOf[ArrayBuffer[Any, String]]
row(0)(0).asInstanceOf[ArrayBuffer[Any]](0).asInstanceOf[Row](0).getString(1)
row(0)(0).asInstanceOf[ArrayBuffer[Any]](0).instanceOf[Array[ArrayBuffer[Any], String]]..but他们谁也不工作。
不过,我还是希望在Scala中有一种更优雅的方式来实现这一点,因为Spark + Scala的整个“管道建造自然”首先吸引了我对这个包的兴趣。
回答 1
Stack Overflow用户
发布于 2015-05-24 18:26:56
正如推特上答复的那样。这个Twitter模式太嵌套了,所以它在一般情况下是相当复杂的。但是,我们可以为将来复杂的嵌套字段添加对访问器的支持,以简化这一点。
Python和Scala版本都附有。
https://stackoverflow.com/questions/30401773
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号