
熊猫资料清单
熊猫资料清单
提问于 2015-05-19 19:31:14
我有一个遵循这种格式的数据集:
data =[[[1, 0, 1000], [2, 1000, 2000]],
[[1, 0, 1500], [2, 1500, 2500], [2, 2500, 4000]]]
var1 = [10.0, 20.0]
var2 = ['ref1','ref2']我想把它转换成一个数据文件:
dic = {'var1': var1, 'var2': var2, 'data': data}
import Pandas as pd
pd.DataFrame(dic)结果:
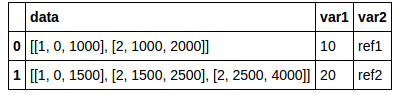
然而,我试图得到这样的东西:
我一直试图把字典[列表]弄平,但没有成功:
pd.DataFrame([[col1, col2] for col1, d in dic.items() for col2 in d])见结果:

不同尺寸的列表使得“拆包”变得复杂到另一个层次。我不确定熊猫在进口到熊猫之前是否能处理好这件事。
回答 2
Stack Overflow用户
回答已采纳
发布于 2015-05-19 20:09:48
创建一个适当的列表是可行的:
new_data = []
for x, v1, v2 in zip(data, var1, var2):
new_data.extend([y + [v1] + [v2] for y in x])
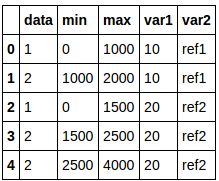
pd.DataFrame(new_data, columns=['data', 'min', 'max', 'var1', 'var2'])给予:
data min max var1 var2
0 1 0 1000 10 ref1
1 2 1000 2000 10 ref1
2 1 0 1500 20 ref2
3 2 1500 2500 20 ref2
4 2 2500 4000 20 ref2Stack Overflow用户
发布于 2015-05-19 20:01:38
我可以迭代临时DataFrame中的行。
df = pd.DataFrame(dic)
result = []
for i,d in df.iterrows():
temp = pd.DataFrame(d['data'], columns=['data', 'min', 'max'])
temp['var1'] = d['var1']
temp['var2'] = d['var2']
result += [temp]
pd.concat(result)这会产生
data min max var1 var2
0 1 0 1000 10 ref1
1 2 1000 2000 10 ref1
0 1 0 1500 20 ref2
1 2 1500 2500 20 ref2
2 2 2500 4000 20 ref2页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/30334554
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号