
如何限制在R包CausalImpact中实现的贝叶斯结构时间序列模型所做的预测?
谷歌的CausalImpact R软件包为贝叶斯结构时间序列建模提供了一个用户友好的界面,它允许一个人在没有一个真正的控制小组的情况下获得反事实的预测和估计因果影响(例如广告活动的效率)。我在使用这个软件时所面临的问题是,在某些情况下,当建模的响应是一个计数变量时,预测间隔和/或预测平均值可能具有负值,这对这些变量来说显然是不可能的。
一个简单的方法是使用响应的日志转换值,然后将结果转换回原始规模(实际上是包的作者的这个方法已经被提到过了。 )。然而,当涉及到对原始规模的结果的解释时,将CausalImpact生成的任何汇总统计数据转换回来并不是非常有帮助的。下面是我的意思--考虑下面的例子:
y = c(7, 18, 11, 3, 3, 2, 89, 94, 48, 74,
21, 13, 5, 9, 10, 18, 12, 4, 8, 4, 12, 8, 6, 7, 6)
x = c(7, 22, 28, 13, 16, 6, 4, 2, 2, 24, 8,
9, 5, 5, 8, 7, 5, 11, 3, 4, 5, 1, 4, 2, 6)
dat = as.ts(cbind(y, x))
pre.period <- c(1, 6)
post.period <- c(7, 25)
library(CausalImpact)
impact <- CausalImpact(dat, pre.period, post.period)
plot(impact)
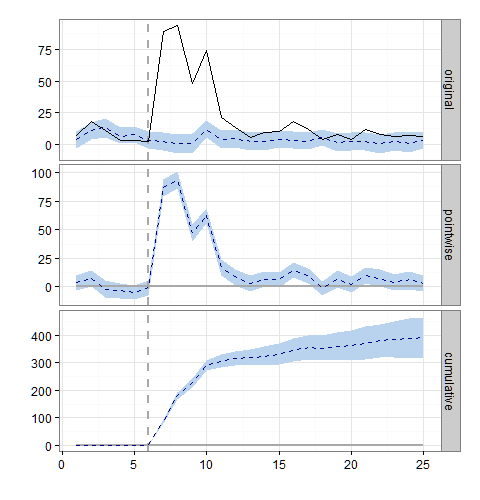
summary(impact)
Posterior inference {CausalImpact}
Average Cumulative
Actual 24 448
Prediction (s.d.) 2.9 (2.1) 54.8 (39.1)
95% CI [-0.98, 6.8] [-18.69, 129.1]
Absolute effect (s.d.) 21 (2.1) 393 (39.1)
95% CI [17, 25] [319, 467]
Relative effect (s.d.) 718% (71%) 718% (71%)
95% CI [582%, 852%] [582%, 852%]
Posterior tail-area probability p: 0.00111
Posterior prob. of a causal effect: 99.88901%
For more details, type: summary(impact, "report")从上面的图表和汇总表中可以看出,实际的95%可信区间包括负值。干预的绝对效果为21,累计- 393,相对- 718%。
现在,让我们在日志转换的响应上重新运行相同的模型:
ylog = log(y)
dat2 = as.ts(cbind(ylog, x))
impactLog <- CausalImpact(dat2, pre.period, post.period)
plot(impactLog)
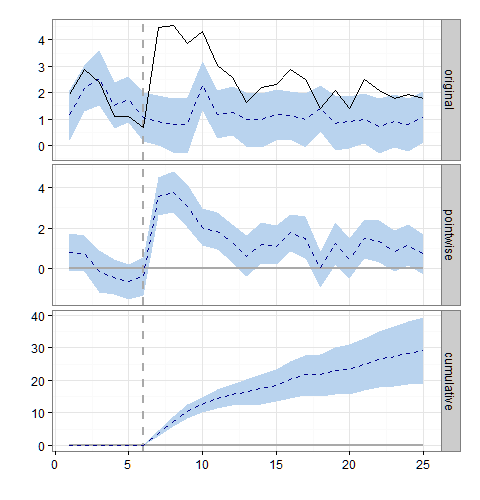
summary(impactLog)
Posterior inference {CausalImpact}
Average Cumulative
Actual 2.6 49.2
Prediction (s.d.) 1.1 (0.28) 20.1 (5.29)
95% CI [0.54, 1.6] [10.17, 30.3]
Absolute effect (s.d.) 1.5 (0.28) 29.2 (5.29)
95% CI [1, 2.1] [19, 39.1]
Relative effect (s.d.) 145% (26%) 145% (26%)
95% CI [94%, 194%] [94%, 194%]
Posterior tail-area probability p: 0.00111
Posterior prob. of a causal effect: 99.88901%
For more details, type: summary(impact, "report")当然,试图从上面的表格中解释反日志转换的影响相关的汇总统计数据,在原始的加性尺度上是没有意义的。例如,绝对值变为exp(1.5) = 4.48,累积效应变为exp(49.2) = 2.33e+21,等等。反日志转换必须对用于构造上述汇总统计数据的原始值进行转换,但我似乎不知道这些原始值位于何处,以及如何在原始标度上计算有意义的汇总统计数据。任何帮助都将不胜感激。
回答 2
Stack Overflow用户
发布于 2019-10-03 07:23:23
对于效果,您可以对response和point.pred进行反日志转换,然后减去以获得效果:
您的原始、非日志结果:
(平均,累计)
> impact$summary$AbsEffect
[1] 20.60043 391.40809要使用日志转换数据获得平均效果:
> mean(exp(impactLog$series$response[7:25,]) - exp(impactLog$series$point.pred[7:25,]))
[1] 20.44092...and累积效应:
> sum(exp(impactLog$series$response[7:25,]) - exp(impactLog$series$point.pred[7:25,]))
[1] 388.3774(这两个结果之间的微小差异是由于MCMC过程中的随机性造成的。)
如果您想要点的效果,它是相同的,但没有mean或sum。
对于绝对平均效应的可信区间:
> # lower
> mean(exp(impactLog$series$response[7:25,]) - exp(impactLog$series$point.pred.upper[7:25,]))
[1] 15.22143
> # upper
> mean(exp(impactLog$series$response[7:25,]) - exp(impactLog$series$point.pred.lower[7:25,]))
[1] 22.40529对于累积可信区间,将mean替换为sum。
Stack Overflow用户
发布于 2016-04-05 00:41:45
为了解释结果,你试过吗?摘要(影响,“报告”)它通常告诉你
“在干预后期间,反应变量的平均值约为24。相反,在没有干预的情况下,我们预计平均反应为3。这一反事实预测的95%间隔为-1,7。从观察到的反应中减去这一预测,可以估计干预对反应变量的因果效应。这一影响为21,95%间隔为17,25。关于这一影响的意义的讨论,见下文。
将干预后期间的单个数据点(有时只能进行有意义的解释)进行总结,响应变量的总价值为448。相比之下,如果不采取干预行动,我们预计将有55美元。这一预测的95%区间为-18,128。
给出了上述结果的绝对值。相对来说,响应变量增加了+718%。这个百分比的95%区间是+585%,+850%。
这意味着干预期间观察到的积极影响在统计上是显著的,不太可能是随机波动造成的。然而,应当指出,只有将绝对效果(21)与根本干预的最初目标进行比较,才能回答这一增加是否也具有实质性意义的问题。
偶然获得这一效应的概率很小(贝叶斯尾区概率p= 0.001)。这意味着因果效应在统计上可以被认为是显著的。“
https://stackoverflow.com/questions/30303680
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号