
为什么在循环之后有一个‘`println`’时,这个循环多次循环的程序需要时间?
这是我正在尝试的小代码。这个程序需要大量的时间来执行。在运行时,如果我试图通过eclipse中的终止按钮关闭它,它将返回Terminate Failed。我可以用kill -9 <PID>从终端杀死它。
但是,当我没有在程序的最后一行中打印变量结果(请检查代码的注释部分)时,程序将立即退出。
我想知道:
- 为什么打印结果的值时执行需要时间?
请注意,如果我不打印
value**,,那么相同的循环将立即结束。** - 为什么eclipse不能杀死程序?
更新1: JVM似乎是在运行时优化代码(而不是在编译时)。这个帖子是有帮助的。
更新2:当我打印value的值时,jstack <PID>无法工作。只有jstack -F <PID>在工作。有可能的原因吗?
public class TestClient {
private static void loop() {
long value =0;
for (int j = 0; j < 50000; j++) {
for (int i = 0; i < 100000000; i++) {
value += 1;
}
}
//When the value is being printed, the program
//is taking time to complete
System.out.println("Done "+ value);
//When the value is NOT being printed, the program
//completes immediately
//System.out.println("Done ");
}
public static void main(String[] args) {
loop();
}
}回答 5
Stack Overflow用户
发布于 2015-05-08 06:18:24
这是一个JIT编译器优化(不是java编译器优化)。
如果将java编译器为这两个版本生成的字节代码进行比较,您将看到在这两个版本中都存在循环。
使用println的反编译方法是这样的:
private static void loop() {
long value = 0L;
for(int j = 0; j < '썐'; ++j) {
for(int i = 0; i < 100000000; ++i) {
++value;
}
}
System.out.println("Done " + value);
}当移除println时,反编译方法就是这样的:
private static void loop() {
long value = 0L;
for(int j = 0; j < '썐'; ++j) {
for(int i = 0; i < 100000000; ++i) {
++value;
}
}
}正如你所看到的,循环仍然存在。
但是,可以使用以下JVM选项启用JIT编译器日志记录和程序集打印:
-XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation -XX:+PrintAssembly您还可能需要下载hsdis-amd64.dylib并放入工作目录(MacOS、HotSpot Java 8)。
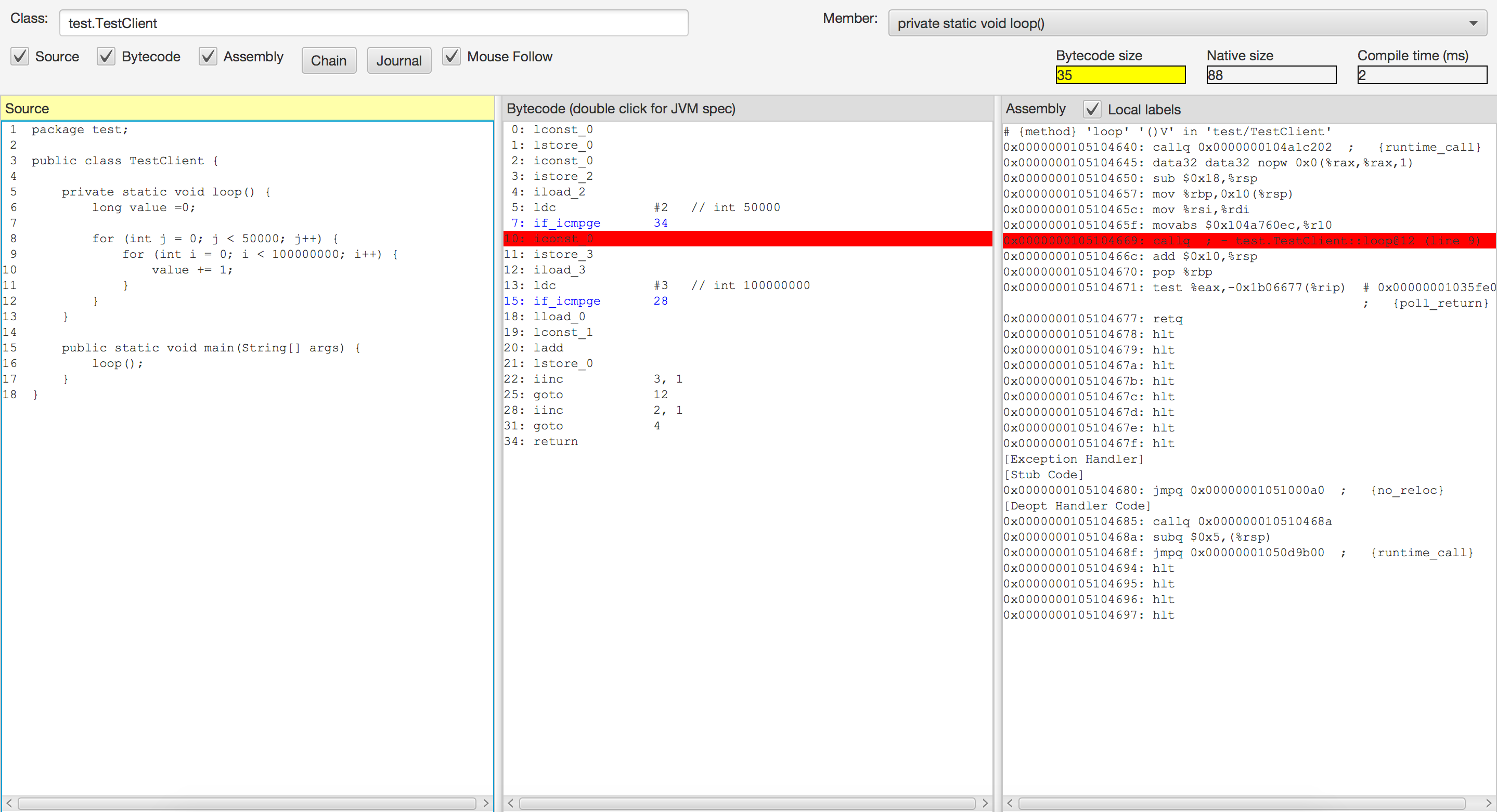
在运行TestClient之后,您应该会在控制台中看到JIT编译器生成的代码。在这里,我只会张贴从输出摘录。
没有println的版本:
# {method} 'loop' '()V' in 'test/TestClient'
0x000000010e3c2500: callq 0x000000010dc1c202 ; {runtime_call}
0x000000010e3c2505: data32 data32 nopw 0x0(%rax,%rax,1)
0x000000010e3c2510: sub $0x18,%rsp
0x000000010e3c2517: mov %rbp,0x10(%rsp)
0x000000010e3c251c: mov %rsi,%rdi
0x000000010e3c251f: movabs $0x10dc760ec,%r10
0x000000010e3c2529: callq *%r10 ;*iload_3
; - test.TestClient::loop@12 (line 9)
0x000000010e3c252c: add $0x10,%rsp
0x000000010e3c2530: pop %rbp
0x000000010e3c2531: test %eax,-0x1c18537(%rip) # 0x000000010c7aa000
; {poll_return}
0x000000010e3c2537: retq带有println的版本:
# {method} 'loop' '()V' in 'test/TestClient'
0x00000001092c36c0: callq 0x0000000108c1c202 ; {runtime_call}
0x00000001092c36c5: data32 data32 nopw 0x0(%rax,%rax,1)
0x00000001092c36d0: mov %eax,-0x14000(%rsp)
0x00000001092c36d7: push %rbp
0x00000001092c36d8: sub $0x10,%rsp
0x00000001092c36dc: mov 0x10(%rsi),%r13
0x00000001092c36e0: mov 0x8(%rsi),%ebp
0x00000001092c36e3: mov (%rsi),%ebx
0x00000001092c36e5: mov %rsi,%rdi
0x00000001092c36e8: movabs $0x108c760ec,%r10
0x00000001092c36f2: callq *%r10
0x00000001092c36f5: jmp 0x00000001092c3740
0x00000001092c36f7: add $0x1,%r13 ;*iload_3
; - test.TestClient::loop@12 (line 9)
0x00000001092c36fb: inc %ebx ;*iinc
; - test.TestClient::loop@22 (line 9)
0x00000001092c36fd: cmp $0x5f5e101,%ebx
0x00000001092c3703: jl 0x00000001092c36f7 ;*if_icmpge
; - test.TestClient::loop@15 (line 9)
0x00000001092c3705: jmp 0x00000001092c3734
0x00000001092c3707: nopw 0x0(%rax,%rax,1)
0x00000001092c3710: mov %r13,%r8 ;*iload_3
; - test.TestClient::loop@12 (line 9)
0x00000001092c3713: mov %r8,%r13
0x00000001092c3716: add $0x10,%r13 ;*ladd
; - test.TestClient::loop@20 (line 10)
0x00000001092c371a: add $0x10,%ebx ;*iinc
; - test.TestClient::loop@22 (line 9)
0x00000001092c371d: cmp $0x5f5e0f2,%ebx
0x00000001092c3723: jl 0x00000001092c3710 ;*if_icmpge
; - test.TestClient::loop@15 (line 9)
0x00000001092c3725: add $0xf,%r8 ;*ladd
; - test.TestClient::loop@20 (line 10)
0x00000001092c3729: cmp $0x5f5e101,%ebx
0x00000001092c372f: jl 0x00000001092c36fb
0x00000001092c3731: mov %r8,%r13 ;*iload_3
; - test.TestClient::loop@12 (line 9)
0x00000001092c3734: inc %ebp ;*iinc
; - test.TestClient::loop@28 (line 8)
0x00000001092c3736: cmp $0xc350,%ebp
0x00000001092c373c: jge 0x00000001092c376c ;*if_icmpge
; - test.TestClient::loop@7 (line 8)
0x00000001092c373e: xor %ebx,%ebx
0x00000001092c3740: mov %ebx,%r11d
0x00000001092c3743: inc %r11d ;*iload_3
; - test.TestClient::loop@12 (line 9)
0x00000001092c3746: mov %r13,%r8
0x00000001092c3749: add $0x1,%r8 ;*ladd
; - test.TestClient::loop@20 (line 10)
0x00000001092c374d: inc %ebx ;*iinc
; - test.TestClient::loop@22 (line 9)
0x00000001092c374f: cmp %r11d,%ebx
0x00000001092c3752: jge 0x00000001092c3759 ;*if_icmpge
; - test.TestClient::loop@15 (line 9)
0x00000001092c3754: mov %r8,%r13
0x00000001092c3757: jmp 0x00000001092c3746
0x00000001092c3759: cmp $0x5f5e0f2,%ebx
0x00000001092c375f: jl 0x00000001092c3713
0x00000001092c3761: mov %r13,%r10
0x00000001092c3764: mov %r8,%r13
0x00000001092c3767: mov %r10,%r8
0x00000001092c376a: jmp 0x00000001092c3729 ;*if_icmpge
; - test.TestClient::loop@7 (line 8)
0x00000001092c376c: mov $0x24,%esi
0x00000001092c3771: mov %r13,%rbp
0x00000001092c3774: data32 xchg %ax,%ax
0x00000001092c3777: callq 0x0000000109298f20 ; OopMap{off=188}
;*getstatic out
; - test.TestClient::loop@34 (line 13)
; {runtime_call}
0x00000001092c377c: callq 0x0000000108c1c202 ;*getstatic out
; - test.TestClient::loop@34 (line 13)
; {runtime_call}另外,您应该有带有JIT编译器步骤的hotspot.log文件。以下是一段节选:
<phase name='optimizer' nodes='114' live='77' stamp='0.100'>
<phase name='idealLoop' nodes='115' live='67' stamp='0.100'>
<loop_tree>
<loop idx='119' >
<loop idx='185' main_loop='185' >
</loop>
</loop>
</loop_tree>
<phase_done name='idealLoop' nodes='197' live='111' stamp='0.101'/>
</phase>
<phase name='idealLoop' nodes='197' live='111' stamp='0.101'>
<loop_tree>
<loop idx='202' >
<loop idx='159' inner_loop='1' pre_loop='131' >
</loop>
<loop idx='210' inner_loop='1' main_loop='210' >
</loop>
<loop idx='138' inner_loop='1' post_loop='131' >
</loop>
</loop>
</loop_tree>
<phase_done name='idealLoop' nodes='221' live='113' stamp='0.101'/>
</phase>
<phase name='idealLoop' nodes='221' live='113' stamp='0.101'>
<loop_tree>
<loop idx='202' >
<loop idx='159' inner_loop='1' pre_loop='131' >
</loop>
<loop idx='210' inner_loop='1' main_loop='210' >
</loop>
<loop idx='138' inner_loop='1' post_loop='131' >
</loop>
</loop>
</loop_tree>
<phase_done name='idealLoop' nodes='241' live='63' stamp='0.101'/>
</phase>
<phase name='ccp' nodes='241' live='63' stamp='0.101'>
<phase_done name='ccp' nodes='241' live='63' stamp='0.101'/>
</phase>
<phase name='idealLoop' nodes='241' live='63' stamp='0.101'>
<loop_tree>
<loop idx='202' inner_loop='1' >
</loop>
</loop_tree>
<phase_done name='idealLoop' nodes='253' live='56' stamp='0.101'/>
</phase>
<phase name='idealLoop' nodes='253' live='56' stamp='0.101'>
<phase_done name='idealLoop' nodes='253' live='33' stamp='0.101'/>
</phase>
<phase_done name='optimizer' nodes='253' live='33' stamp='0.101'/>
</phase>您可以使用hotspot.log工具https://github.com/AdoptOpenJDK/jitwatch/wiki进一步分析JIT编译器生成的JitWatch文件。
要禁用JIT编译器并在所有解释模式下运行-Djava.compiler=NONE虚拟机,您可以使用Java选项。
类似的问题出现在本文的为什么我的JVM要做一些运行时循环优化,并使我的代码错误?中。
Stack Overflow用户
发布于 2015-05-08 06:06:33
这是因为编译器/JVM优化。当您打印结果时,计算和编译器将保持循环。
另一方面,当您不使用循环中的任何内容时,编译器/JVM将删除该循环。
Stack Overflow用户
发布于 2015-05-08 06:17:32
基本上,JVM实际上是非常的智能。它可以感知您是否正在使用任何变量,并且基于此,它实际上可以删除与此相关的任何处理。因为您注释掉了打印"value“的代码行,所以它感觉到这个变量不会在任何地方使用,并且不会运行循环,甚至一次都不会运行。
但是,当执行打印值时,它必须运行循环,这也是一个非常大的数字(50000 * 100000000)。现在,这个循环的运行时间取决于您的许多因素,包括但不限于机器的处理器、给JVM的内存、处理器的负载等等。
至于您的eclipse不能终止它的问题,我可以很容易地使用eclipse在我的机器上杀死这个程序。也许你应该再检查一次。
https://stackoverflow.com/questions/30116664
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号