
算法:分而治之与时间复杂度O(nlogn)有何关系?
在我的算法和数据结构类中,引入了第一个divide-and-conquer algorithm,即merge sort。
在执行作业算法时,我想到了几个问题。
- 使用分而治之范式实现的算法是否具有O(nlogn)的时间复杂度?
- 方法中的递归部分是否具有将运行在O(n^2)中的算法压缩为O(nlogn)的能力?
- 是什么使得这样的算法首先在O(nlogn)中运行?
对于(3),我假设这与递归树和可能的递归次数有关。有人可能会用一个运行在O(nlogn)中的简单的分而治之算法来显示,它的复杂度是如何计算的呢?
干杯,安德鲁
回答 4
Stack Overflow用户
发布于 2015-04-28 22:18:23
我认为你的问题的所有答案都可能来自主定理 --它告诉你,几乎所有的分而治之的解决方案,你的复杂性是什么?是的,它必须用递归树来做所有事情,通过处理参数,你会发现一些分而治之的解决方案不会有O(nlogn)的复杂性,事实上有具有O(n)复杂度的分治算法。
关于问题2,并不总是可能的,事实上,有些问题被认为是不可能比O(n^2)更快地解决的,这取决于问题的性质。
MergeSort是一个运行在O(nlogn)中的算法的例子,我认为它有一个非常简单、清晰和有教育意义的运行时分析。可以从以下图片中了解到这一点:
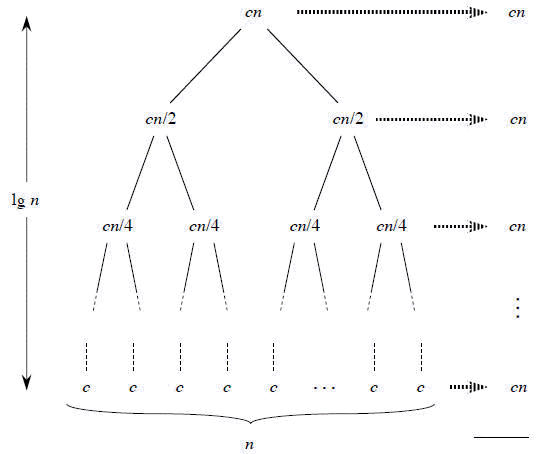
因此,每一个递归步骤--输入被分成两部分,然后征服部分取O(n),所以树的每一层代价为O(n),最棘手的部分可能是递归级别(树高)的数目是否可能被指定。这或多或少是简单的。因此,在每一步中,我们将输入分成n/2元素的两个部分,然后递归地重复,直到我们得到一些恒定大小的输入。在第一层,我们将n/2除以下一个n/4,然后再除以n/8,直到达到一个恒定大小的输入,这将是树的一个叶,最后一个递归步骤。
因此,在第一个递归步骤中,我们除以n/2^i,让我们在最后一步找到i的值。我们需要n/2^i = O(1),当2^i = cn时,对于一些常数c,我们从两边取基2对数,得到I= clogn。所以最后的递归步骤是第四步,这样树就有了高度。
因此,MergeSort的总成本将是cn,用于每个clogn递归(树)级别,这就带来了O(nlogn)的复杂性。
通常,只要递归步骤具有O( n )复杂性,您就可以确信算法将具有O(nlogn)复杂度,并且,如果部分是n的线性分数,则很可能有不同的运行时,并且yo会讨论大小为n/b的b问题,甚至更一般的问题。
回到问题2,在QuickSort的情况下,可能从O(n^2)到\Theta(nlogn)恰恰是因为平均随机情况实现了一个很好的分区,尽管运行时分析甚至比这更复杂。
Stack Overflow用户
发布于 2015-04-28 18:53:24
不,分而治之并不能保证O(nlogn)的性能。这完全取决于每个递归是如何简化问题的。
在合并排序算法中,原问题分为两部分。然后对结果执行O(n)操作。这就是O(n.)来自于。
现在,这两个子操作中的每个子操作都有自己的n,大小是原始操作的一半。每次你回忆,你再把问题分成两半。这意味着递归的数量将是log2(n)。这就是O(...logn)的来源。
Stack Overflow用户
发布于 2015-04-28 18:59:18
使用分而治之范式实现的算法是否具有O(nlogn)的时间复杂度?
平均而言,快速排序和Mergesort的时间复杂度为O(n log(n)),但并不总是这样。大O备忘单
方法中的递归部分是否具有将运行在类似O(n^2)到O(nlogn)的算法压缩的能力?
这不仅仅取决于其他事情,比如每个递归调用与输入相关的操作数。
我强烈推荐这个视频,您可以看到为什么MergeSort是O(n (N))。
首先,是什么使这样的算法在O(nlogn)中运行。
同样,这只是一个算法与输入大小相关所消耗的时间的指标,所以说一个算法的时间复杂度为O (n log (n))并不能给出算法是如何实现的任何信息,它只是说当输入开始大幅度增加时,所用的时间不会成正比地增加,而是需要越来越多的时间。
https://stackoverflow.com/questions/29927439
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号