
火花点互信息的计算
火花点互信息的计算
提问于 2015-04-14 06:11:27
我正在计算点态互信息 (PMI)。
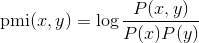
对于p(x,y)和p(x),我分别定义了两个RDDs:
pii: RDD[((String, String), Double)]
pi: RDD[(String, Double)]我编写的从RDDs、pii和pi计算PMI的任何代码都不太好看。我的方法首先是在传递元组元素的同时,平缓RDD pii并与pi连接两次。
val pmi = pii.map(x => (x._1._1, (x._1._2, x._1, x._2)))
.join(pi).values
.map(x => (x._1._1, (x._1._2, x._1._3, x._2)))
.join(pi).values
.map(x => (x._1._1, computePMI(x._1._2, x._1._3, x._2)))
// pmi: org.apache.spark.rdd.RDD[((String, String), Double)]
...
def computePMI(pab: Double, pa: Double, pb: Double) = {
// handle boundary conditions, etc
log(pab) - log(pa) - log(pb)
}显然这糟透了。有没有更好的(惯用的)方法来做这件事?注意:我可以通过在pi和pii中存储日志问题来优化日志,但是选择用这种方式来保持问题的清晰性。
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-04-15 03:05:04
使用broadcast将是一个解决方案。
val bcPi = pi.context.broadcast(pi.collectAsMap())
val pmi = pii.map {
case ((x, y), pxy) =>
(x, y) -> computePMI(pxy, bcPi.value.get(x).get, bcPi.value.get(y).get)
}假设:pi拥有pii中的所有x和y。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/29620297
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号