
非球面扰动引起的结构自举检验统计量
我试图在一个时间序列的平均值中找到一个结构性的断裂,这个序列是倾斜的,肥尾的,异方差的。我应用安德鲁斯(1993)超F-测试通过结构改变包。我的理解是,这是有效的,即使在我的非球面扰动。但我想通过引导来证实这一点。我想从每个可能的断点(就像Andrews estimate一样)的平均值测试的差异中估计最大t-stat值,然后引导临界值。换句话说,我想在按时间顺序的数据中找到我的最大t-stat值。然后对数据进行置乱,在加扰后的数据中找到最大值t-stat,10,000次.然后将时间有序数据中的最大t-stat与无序数据中的9,500最大t-stat的临界值进行比较。下面我生成示例数据并应用Andrews supF测试。有没有办法“纠正”安德鲁斯试验的非球面干扰?有什么办法来做我想做的事吗?
library(strucchange)
Thames <- ts(matrix(c(rlnorm(120, 0, 1), rlnorm(120, 2, 2), rlnorm(120, 4, 1)), ncol = 1), frequency = 12, start = c(1985, 1))
fs.thames <- Fstats(Thames ~ 1)
sctest(fs.thames)回答 2
Stack Overflow用户
发布于 2015-04-12 19:58:56
(1)偏斜和重尾与通常的线性回归模型一样,它的渐近正态性不依赖于正态分布,而且在零期望、同方差性和缺乏相关性(通常的Gauss假设)的情况下也适用于任何其他误差分布。但是,如果您对感兴趣的数据有一个很好的拟合的倾斜分布,那么您可以通过基于相应模型的推理来提高效率。例如,glogis包提供了一些基于广义逻辑分布的结构变化测试和测年功能,该分布允许重尾和偏度。Windberger & Zeileis (2014年,东欧经济出版社,52,66-88,doi:10.2753/doi 0012-8775520304)利用这一方法跟踪通货膨胀动态偏度随时间的变化。(有关工作示例,请参阅?breakpoints.glogisfit。)此外,如果倾斜本身并不真正感兴趣,那么日志或sqrt转换也可能足够好,使数据更加“正常”。
(2)异方差和自相关,在线性回归模型中,标准误差(或更广义的协方差矩阵)在异方差和(或)自相关的存在下是不一致的。我们可以尝试在模型(例如AR模型)中显式地包含这一点,或者将它作为一个讨厌项来处理,并使用异方差和自相关协方差矩阵(例如Newey或Andrews的二次谱核HAC)。Fstats()函数在strucchange中允许插入这样的估值器,例如从sandwich包中插入。有关使用?durab的示例,请参见vcovHC()。
(3)引导和置换p-值。上面描述的时间序列的“置乱”听起来更像是应用置换(即不替换的采样),而不是引导(即用替换的采样)。当误差不相关或可交换时,前者是可行的。如果您只是在常量上进行回归,那么您可以使用coin包中的函数coin来执行supF测试。测试统计量是以一种有点不同的方式计算的,然而,这可以被证明是等价于仅在常数情况下的supF检验(见Zeileis & Hothorn,2013年,统计论文,54,931-954,指定用途:10.1007/s 00362-013-0503-4)。如果您想要在一个更通用的模型中执行置换测试,那么您将不得不“手工”进行排列,并简单地存储来自每个置换的测试统计信息。或者,可以应用引导,例如通过boot包(您仍然需要编写自己的小函数,该函数从给定的引导示例中计算测试统计信息)。还有一些R包(例如,tseries)实现了依赖序列的引导方案。
Stack Overflow用户
发布于 2015-04-14 09:04:17
我正在添加第二个答案来分析所提供的模拟Thames数据。关于我的第一个一般方法答案中的要点:(1)在这种情况下,log()变换显然适合于处理观测结果的极端偏斜。(2)由于数据是异方差的,推断应以HC或HAC协方差为基础。下面我使用Newey估计,虽然这些数据是异方差的,但不是自相关的。HAC修正的推断影响supF检验和断点估计的置信区间.断点本身和相应的分段特定截取被OLS估计,即把异方差作为一个干扰项来处理。(3)在这种情况下,我没有添加任何引导或置换推理,因为渐近推理似乎是足够令人信服的。
首先,我们使用一个特定的种子来模拟数据。(请注意,其他种子在分析该系列的水平时,可能不会导致如此明确的断点估计。)
library("strucchange")
set.seed(12)
Thames <- ts(c(rlnorm(120, 0, 1), rlnorm(120, 2, 2), rlnorm(120, 4, 1)),
frequency = 12, start = c(1985, 1))然后计算了HAC修正的Wald/F统计量序列,估计了最优断点(m= 1,2,3,…通过苏丹生命线行动。为了说明这个系列在日志中而不是在级别上有多好,这两个版本都显示了。
fs_lev <- Fstats(Thames ~ 1, vcov = NeweyWest)
fs_log <- Fstats(log(Thames) ~ 1, vcov = NeweyWest)
bp_lev <- breakpoints(Thames ~ 1)
bp_log <- breakpoints(log(Thames) ~ 1) 下面的可视化显示了第一行截取的时间序列,第二行supF检验5%临界值的Wald/F统计量序列,最后一行断点数目选择的残差平方和。复制图形的代码位于这个答案的末尾。
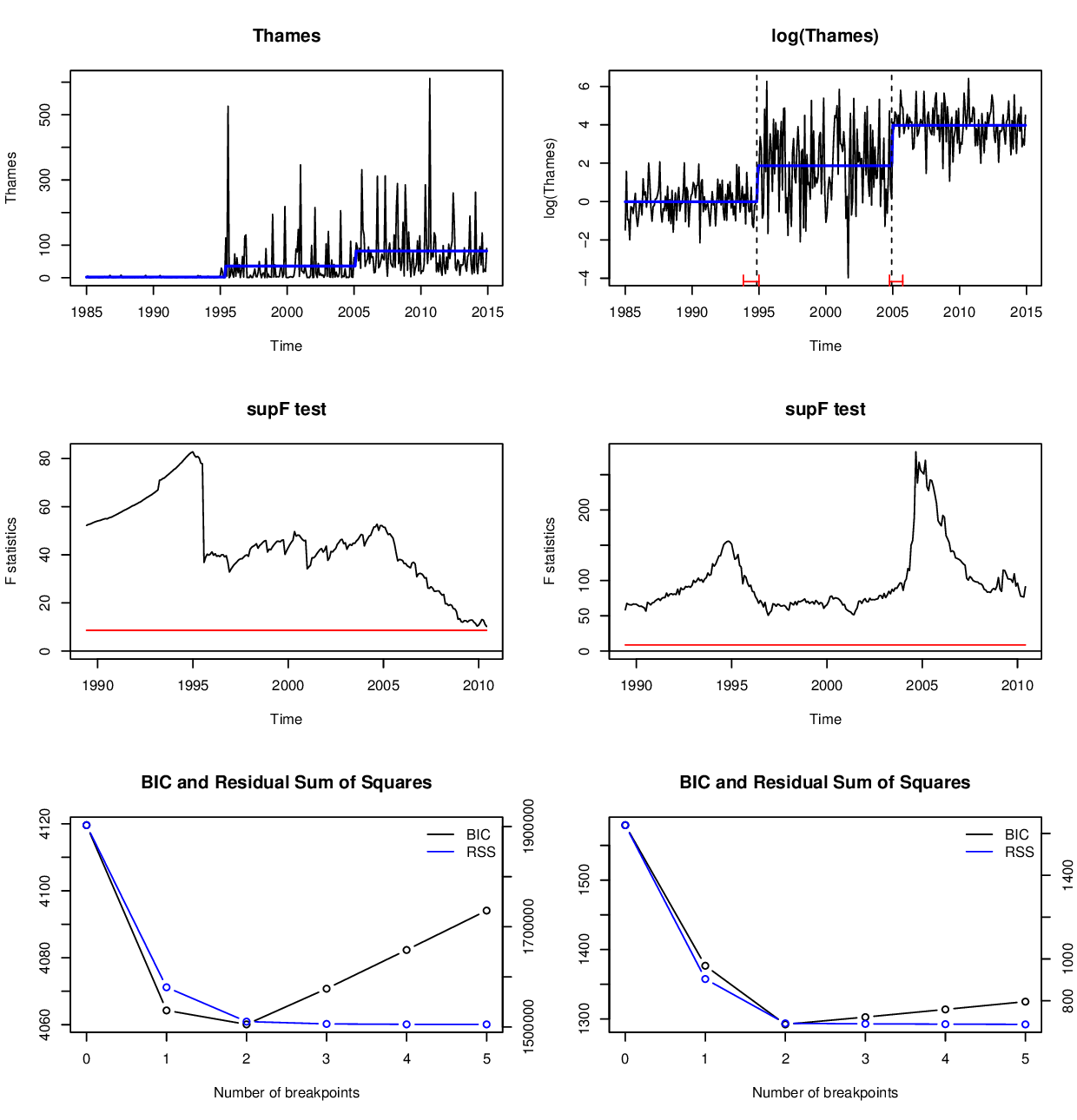
这两个supF测试显然都很重要,但在级别(sctest(fs_lev))中,测试统计量“仅”为82.79,而在日志(sctest(fs_log))中为282.46。此外,在分析日志中的数据时,可以更好地看到与这两个断点相关的两个峰值。
同样,对于日志转换数据,断点估计值要好一些,置信区间也要窄得多。在层次上,我们得到:
confint(bp_lev, breaks = 2, vcov = NeweyWest)
##
## Confidence intervals for breakpoints
## of optimal 3-segment partition:
##
## Call:
## confint.breakpointsfull(object = bp_lev, breaks = 2, vcov. = NeweyWest)
##
## Breakpoints at observation number:
## 2.5 % breakpoints 97.5 %
## 1 NA 125 NA
## 2 202 242 263再加上一条错误信息和警告,这些都反映了渐近推断在这里不是一个有用的近似。相反,对于日志分析,置信区间是相当合理的。由于中间部分的差异增加,其开始和结束比第一和最后一段要更不确定:
confint(bp_log, breaks = 2, vcov = NeweyWest)
##
## Confidence intervals for breakpoints
## of optimal 3-segment partition:
##
## Call:
## confint.breakpointsfull(object = bp_log, breaks = 2, vcov. = NeweyWest)
##
## Breakpoints at observation number:
## 2.5 % breakpoints 97.5 %
## 1 107 119 121
## 2 238 240 250
##
## Corresponding to breakdates:
## 2.5 % breakpoints 97.5 %
## 1 1993(11) 1994(11) 1995(1)
## 2 2004(10) 2004(12) 2005(10)最后,这里包含了上面图的复制代码。由于上述错误,无法在图形中添加断点的置信区间。因此,只有对数变换序列也有置信区间.
par(mfrow = c(3, 2))
plot(Thames, main = "Thames")
lines(fitted(bp_lev, breaks = 2), col = 4, lwd = 2)
plot(log(Thames), main = "log(Thames)")
lines(fitted(bp_log, breaks = 2), col = 4, lwd = 2)
lines(confint(bp_log, breaks = 2, vcov = NeweyWest))
plot(fs_lev, main = "supF test")
plot(fs_log, main = "supF test")
plot(bp_lev)
plot(bp_log)https://stackoverflow.com/questions/29591693
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号