
MongoDB并发瓶颈
太久了;没有读
这个问题是关于我在MongoDB上遇到的并发瓶颈。如果我执行一个查询,则返回一个单位的时间;如果进行两个并发查询,都需要两个单位的时间返回;通常,如果进行n个并发查询,则所有查询都需要n个时间单位返回。我的问题是,在遇到并发查询时,如何改进Mongo的响应时间?
设置
我在AWS上有一个运行MongoDB 2.6.7服务器的m3.media实例。M3.media有1 vCPU (XeonE5-2670 v2的核心)、3.75GB和4GB的SSD。
我有一个数据库,其中包含一个名为user_products的集合。此集合中的文档具有以下结构:
{ user: <int>, product: <int> }有1000个用户和1000个产品,每个用户-产品对都有一个文档,总计100万个文档。
集合有一个索引{ user: 1, product: 1 },下面的结果都是indexOnly。
考试
测试是在运行MongoDB的同一台机器上执行的。我正在使用与Mongo提供的benchRun函数。在测试期间,不进行对MongoDB的其他访问,测试只包括读取操作。
对于每个测试,模拟多个并发客户端,每个客户端尽可能多次地进行单个查询,直到测试结束。每个测试运行10秒。并发性被测试为2的幂,从1到128个同时客户端。
运行测试的命令:
mongo bench.js下面是完整的脚本(bench.js):
var
seconds = 10,
limit = 1000,
USER_COUNT = 1000,
concurrency,
savedTime,
res,
timediff,
ops,
results,
docsPerSecond,
latencyRatio,
currentLatency,
previousLatency;
ops = [
{
op : "find" ,
ns : "test_user_products.user_products" ,
query : {
user : { "#RAND_INT" : [ 0 , USER_COUNT - 1 ] }
},
limit: limit,
fields: { _id: 0, user: 1, product: 1 }
}
];
for (concurrency = 1; concurrency <= 128; concurrency *= 2) {
savedTime = new Date();
res = benchRun({
parallel: concurrency,
host: "localhost",
seconds: seconds,
ops: ops
});
timediff = new Date() - savedTime;
docsPerSecond = res.query * limit;
currentLatency = res.queryLatencyAverageMicros / 1000;
if (previousLatency) {
latencyRatio = currentLatency / previousLatency;
}
results = [
savedTime.getFullYear() + '-' + (savedTime.getMonth() + 1).toFixed(2) + '-' + savedTime.getDate().toFixed(2),
savedTime.getHours().toFixed(2) + ':' + savedTime.getMinutes().toFixed(2),
concurrency,
res.query,
currentLatency,
timediff / 1000,
seconds,
docsPerSecond,
latencyRatio
];
previousLatency = currentLatency;
print(results.join('\t'));
}结果
结果总是这样(为了便于理解,省略了一些输出列):
concurrency queries/sec avg latency (ms) latency ratio
1 459.6 2.153609008 -
2 460.4 4.319577324 2.005738882
4 457.7 8.670418178 2.007237636
8 455.3 17.4266174 2.00989353
16 450.6 35.55693474 2.040380754
32 429 74.50149883 2.09527338
64 419.2 153.7325095 2.063482104
128 403.1 325.2151235 2.115460969如果只有一个客户端处于活动状态,那么它能够在10秒测试中每秒执行460次查询。查询的平均响应时间约为2ms。
当两个客户端同时发送查询时,查询吞吐量保持在每秒460个查询,这表明Mongo没有增加其响应吞吐量。另一方面,平均延迟则是原来的两倍。
对于4个客户端,这种模式仍在继续。相同的查询吞吐量,对于运行的两个客户端,平均延迟会加倍。列latency ratio是当前测试与先前测试的平均延迟之间的比率。确保它总是显示延迟加倍。
更新:更多CPU功率
我决定用不同的实例类型进行测试,改变vCPU的数量和可用RAM的数量。目的是看看当你增加更多的CPU能力时会发生什么。测试的实例类型:
Type vCPUs RAM(GB)
m3.medium 1 3.75
m3.large 2 7.5
m3.xlarge 4 15
m3.2xlarge 8 30以下是研究结果:
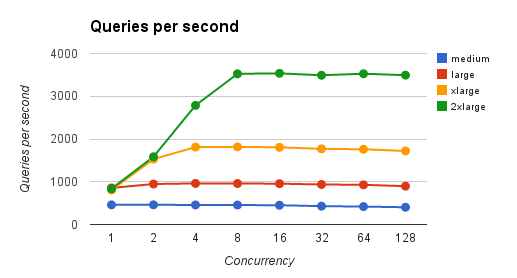
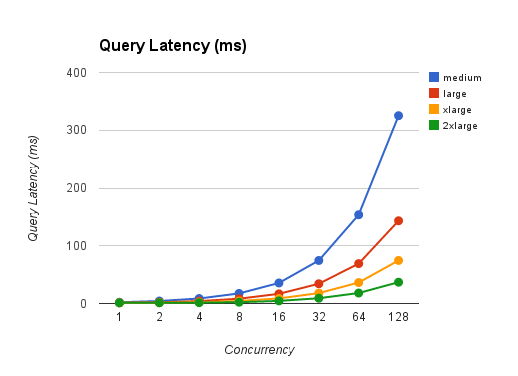
m3.介质
concurrency queries/sec avg latency (ms) latency ratio
1 459.6 2.153609008 -
2 460.4 4.319577324 2.005738882
4 457.7 8.670418178 2.007237636
8 455.3 17.4266174 2.00989353
16 450.6 35.55693474 2.040380754
32 429 74.50149883 2.09527338
64 419.2 153.7325095 2.063482104
128 403.1 325.2151235 2.115460969m3.大型
concurrency queries/sec avg latency (ms) latency ratio
1 855.5 1.15582069 -
2 947 2.093453854 1.811227185
4 961 4.13864589 1.976946318
8 958.5 8.306435055 2.007041742
16 954.8 16.72530889 2.013536347
32 936.3 34.17121062 2.043083977
64 927.9 69.09198599 2.021935563
128 896.2 143.3052382 2.074122435m3.xlarge
concurrency queries/sec avg latency (ms) latency ratio
1 807.5 1.226082735 -
2 1529.9 1.294211452 1.055566166
4 1810.5 2.191730848 1.693487447
8 1816.5 4.368602642 1.993220402
16 1805.3 8.791969257 2.01253581
32 1770 17.97939718 2.044979532
64 1759.2 36.2891598 2.018374668
128 1720.7 74.56586511 2.054769676m3.2x大型
concurrency queries/sec avg latency (ms) latency ratio
1 836.6 1.185045183 -
2 1585.3 1.250742872 1.055438974
4 2786.4 1.422254414 1.13712774
8 3524.3 2.250554777 1.58238551
16 3536.1 4.489283844 1.994745425
32 3490.7 9.121144097 2.031759277
64 3527 18.14225682 1.989033023
128 3492.9 36.9044113 2.034168718从xlarge类型开始,我们开始看到它最终处理两个并发查询,同时保持查询延迟几乎相同(1.29ms)。但是,它不会持续太久,而且对于4个客户端来说,它再次使平均延迟翻了一番。
使用2xlarge类型,Mongo能够在不增加平均延迟的情况下处理多达4个并发客户端。在那之后,它又开始翻倍。
问题是:可以做些什么来提高Mongo对并发查询的响应时间呢?,我预期查询吞吐量会增加,但我没想到它会使平均延迟翻一番。它清楚地表明,Mongo无法并行处理即将到达的查询。
有一些瓶颈限制了Mongo,但它肯定无助于增加更多的CPU能力,因为成本将是令人望而却步的。我不认为内存是一个问题,因为我的整个测试数据库适合RAM很容易。还有什么我可以试试的吗?
回答 1
Stack Overflow用户
发布于 2015-04-07 18:50:36
您使用的是具有1核心的服务器,使用的是benchRun。来自benchRun页面
这个benchRun命令是作为QA基线性能度量工具设计的;它不是一个“基准”。
使用并发数对延迟进行缩放是可疑的。你确定这个计算是正确的吗?我可以相信,随着跑步者数量的增加,操作系统/秒/运行程序保持不变,延迟/运行时间也保持不变--然后如果添加所有延迟,就会看到类似于您的结果。
https://stackoverflow.com/questions/29493883
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号