
clojure懒惰-seq性能优化
我对Clojure相当陌生,我有一些正在尝试优化的代码。我想计算并发计数。主要函数是计算空间,输出是类型的嵌套映射。
{"w1" {"w11" 10, "w12" 31, ...}
"w2" {"w21" 14, "w22" 1, ...}
...
}意思是"w1“和"w11”共发生10次,等等.
它需要一个文档(句子)和一个目标词的集合,它对这两个词进行迭代,并最终应用上下文-fn(例如滑动窗口)来提取上下文词。更具体地说,我是通过滑动窗口关闭的。
(compute-space docs (fn [target doc] (sliding-window target doc 5)) targets)我一直在用大约5000万字(约300万句话)和大约2万条目标来测试它。这个版本需要超过一天的时间才能完成。我还编写了一个pmap并行函数(Pcompute Space),它可以将计算时间缩短到10小时左右,但我仍然觉得它应该更快。我没有其他代码可以比较,但我的直觉说它应该更快。
(defn compute-space
([docs context-fn targets]
(let [space (atom {})]
(doseq [doc docs
target targets]
(when-let [contexts (context-fn target doc)]
(doseq [w contexts]
(if (get-in @space [target w])
(swap! space update-in [target w] (partial inc))
(swap! space assoc-in [target w] 1)))))
@space)))
(defn sliding-window
[target s n]
(loop [todo s seen [] acc []]
(let [curr (first todo)]
(cond (= curr target) (recur (rest todo) (cons curr seen) (concat acc (take n seen) (take n (rest todo))))
(empty? todo) acc
:else (recur (rest todo) (cons curr seen) acc)))))
(defn pcompute-space
[docs step context-fn targets]
(reduce
#(deep-merge-with + %1 %2)
(pmap
(fn [chunk]
(do (tick))
(compute-space chunk context-fn targets))
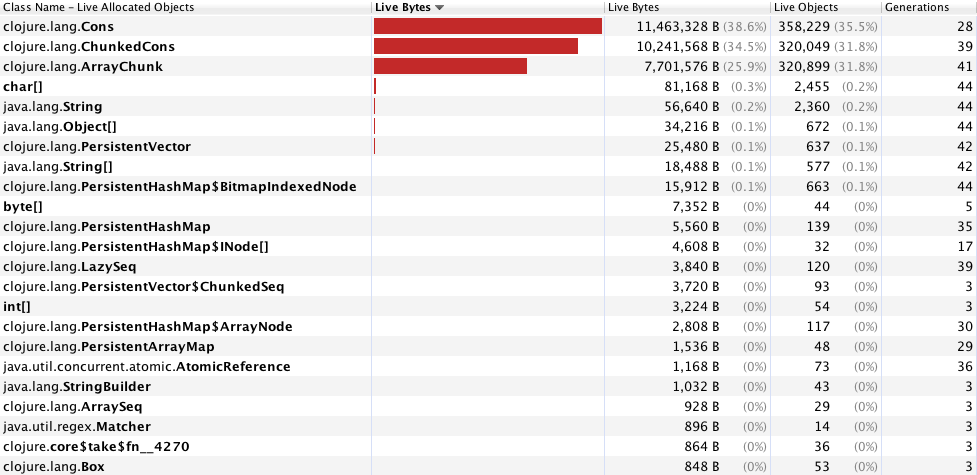
(partition-all step docs)))我用jvisualvm对应用程序进行了描述,发现clojure.lang.Cons、clojure.lang.ChunkedCons和clojure.lang.ArrayChunk过度地控制了这个过程(见图)。这肯定与我使用这个双剂量的循环有关,(以前的实验表明,这种方法比使用map、还原等方法更快,尽管我使用时间来基准这些函数)。我非常感谢您能为我提供的任何见解,以及关于重构代码并使其运行得更快的建议。我想减速机在这里可能会有所帮助,但我不确定如何和/或为什么。
规范
MacPro 2010 2,4 GHz Intel Core 2 2 GB RAM
Clojure 1.6.0
Java 1.7.0_51 HotSpot(TM) 64位服务器VM
回答 2
Stack Overflow用户
发布于 2015-04-08 05:03:41
试验数据如下:
- 一个由42个字符串(目标)组成的延迟的seq
- 由105,040套懒集组成的懒集。(文件)
- 文档中的每个延迟的seq都是字符串的惰性序列。文件中包含的字符串总数为1 146 190条。
比你的工作量小很多。用黄曲霉收集时间。Criterium多次计算一个表达式,首先对JIT进行热身,然后收集平均数据。
使用我的测试数据和代码,compute-space花费了22秒:
WARNING: JVM argument TieredStopAtLevel=1 is active, and may lead to unexpected results as JIT C2 compiler may not be active. See http://www.slideshare.net/CharlesNutter/javaone-2012-jvm-jit-for-dummies.
Evaluation count : 60 in 60 samples of 1 calls.
Execution time mean : 21.989189 sec
Execution time std-deviation : 471.199127 ms
Execution time lower quantile : 21.540155 sec ( 2.5%)
Execution time upper quantile : 23.226352 sec (97.5%)
Overhead used : 13.353852 ns
Found 2 outliers in 60 samples (3.3333 %)
low-severe 2 (3.3333 %)
Variance from outliers : 9.4329 % Variance is slightly inflated by outliers第一次优化更新为使用frequencies从单词向量到单词映射和出现次数。
为了帮助我理解计算的结构,我编写了一个单独的函数,它接受文档、context-fn和单个目标的集合,并将上下文单词的映射返回计数。compute-space返回的一个目标的内部映射。编写这篇文章时使用了内置的Clojure函数,而不是更新计数。
(defn compute-context-map-f [documents context-fn target]
(frequencies (mapcat #(context-fn target %) documents)))使用compute-context-map-f编写的compute-space (名为compute-space-f here )相当短:
(defn compute-space-f [docs context-fn targets]
(into {} (map #(vector % (compute-context-map-f docs context-fn %)) targets)))与上述数据相同的时间是原始版本的65%:
WARNING: JVM argument TieredStopAtLevel=1 is active, and may lead to unexpected results as JIT C2 compiler may not be active. See http://www.slideshare.net/CharlesNutter/javaone-2012-jvm-jit-for-dummies.
Evaluation count : 60 in 60 samples of 1 calls.
Execution time mean : 14.274344 sec
Execution time std-deviation : 345.240183 ms
Execution time lower quantile : 13.981537 sec ( 2.5%)
Execution time upper quantile : 15.088521 sec (97.5%)
Overhead used : 13.353852 ns
Found 3 outliers in 60 samples (5.0000 %)
low-severe 1 (1.6667 %)
low-mild 2 (3.3333 %)
Variance from outliers : 12.5419 % Variance is moderately inflated by outliers并行第一次优化
我选择逐块而不是文档,这样合并映射在一起就不需要修改目标的{context-word count, ...}映射。
(defn pcompute-space-f [docs step context-fn targets]
(into {} (pmap #(compute-space-f docs context-fn %) (partition-all step targets))))与上述数据相同的时间是原版本的16%:
user> (criterium.core/bench (pcompute-space-f documents 4 #(sliding-window %1 %2 5) keywords))
WARNING: JVM argument TieredStopAtLevel=1 is active, and may lead to unexpected results as JIT C2 compiler may not be active. See http://www.slideshare.net/CharlesNutter/javaone-2012-jvm-jit-for-dummies.
Evaluation count : 60 in 60 samples of 1 calls.
Execution time mean : 3.623018 sec
Execution time std-deviation : 83.780996 ms
Execution time lower quantile : 3.486419 sec ( 2.5%)
Execution time upper quantile : 3.788714 sec (97.5%)
Overhead used : 13.353852 ns
Found 1 outliers in 60 samples (1.6667 %)
low-severe 1 (1.6667 %)
Variance from outliers : 11.0038 % Variance is moderately inflated by outliersSpecifications
- Mac 2009 2.66 GHz四核英特尔Xeon,48 GB内存.
- Clojure 1.6.0.
- Java 1.8.0_40 HotSpot(TM) 64位服务器VM.
TBD
进一步优化。
描述测试数据。
Stack Overflow用户
发布于 2015-04-10 12:17:07
compute-space 算法在问题中的分析
扫描句子的成本-寻找目标-
- 与字数成正比。
- 与目标数量成正比,但是
- 更少地独立于单词被分成的句子的数量。
处理目标的费用
- 与目标命中率成正比,
- 与上下文中不同单词的数量成正比。
主要改进
context-fn扫描一个句子,寻找目标。如果有一万目标,它会扫描这个句子一万次。
最好把句子扫描一遍,找出所有的目标。如果我们将目标保持为(散列)集,那么无论有多少个目标,我们都可以在大致恒定的时间内测试一个单词是否是一个目标。
可能改进的
sliding-windows函数通过将每个单词从一个单词传递到另一个单词(从todo到seen )来生成上下文。更快的方法可能是将单词倒进向量,然后以subvec的形式返回上下文。
无论如何,组织生成上下文的一种简单方法是让context-fn返回与单词序列相对应的上下文序列。为sliding-windows执行此操作的函数是
(defn sliding-windows [w s]
(let [v (vec s), n (count v)
window (fn [i] (lazy-cat (subvec v (max (- i w) 0) i)
(subvec v (inc i) (min (inc (+ i w)) n))))]
(map window (range n))))现在,我们可以按照新类型的compute-space定义contexts-fn函数如下:
(defn compute-space [docs contexts-fn target?]
(letfn [(stuff [s] (->> (map vector s (contexts-fn s))
(filter (comp target? first))))]
(reduce
(fn [a [k m]] (assoc a k (merge-with + (a k) (frequencies m))))
{}
(mapcat stuff docs))))代码在stuff上的支点
- 我们把
stuff发展成一个[target context-sequence]对序列。 - 然后,我们将每对合并到聚合中,为每个目标的出现添加相应的邻居计数。
结果
这个算法比问题中的算法快500倍:问题中的代码在一天半内完成了什么,这应该在大约一分钟内完成。
给定的
- 10万字的词汇量,
- 一句100,000字,
- 10,000个目标
此代码在100毫秒内构造上下文映射。
对于十分之一的长句-- 10,000字--问题中的代码需要5秒。
这是使用(长)整数而不是字符串作为“单词”。因此,将字符串与其哈希值组装在一起的工作将在一定程度上削弱这种改进。
Note
我把这个答案的原稿写下来是因为
- 编码中存在转录错误;
- 业绩索赔不准确。
使用Criterium进行的精确测试--使用瞬态映射的版本--被证明稍微慢了一点,因此被省略了。
https://stackoverflow.com/questions/29492140
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号