
jqGrid filterToolbar不区分大小写的搜索找不到特殊的土耳其字符
我在使用jqGrid filterToolbar时遇到了问题。工具栏进行搜索,但找不到包含"ı"的字符。例如,我可以搜索"yapi"单词,但是搜索工具栏找不到"yapı"。
jQuery("#grid-table").jqGrid('filterToolbar',
{ stringResult: false, searchOperators: false, defaultSearch: "cn" });我的页面编码是;
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />我的ajax帖子就在这里
$.ajax({ type:"Post",url:"page/get.aspx,contentType:"application/json;charset=utf-8",dataType:"json",数据:"{}",成功:函数() {/ },错误:函数() {/ });
回答 1
Stack Overflow用户
发布于 2015-04-02 14:49:08
我确信问题在于您使用的HTML页面的编码。我试图重现这个问题,并打开了一个用ANSI编码保存的旧演示。在我将测试yapı插入数据并保存之后,我可以再现这个问题,但是对代码的验证表明,由于ANSI编码,字符串yapı被保存为yapi。然后,我使用记事本(我在Windows计算机上工作)打开相同的演示,重复相同的演示,并使用SaveAs可以选择UTF-8编码。现在,人们可以看到真正的yapı字符串显示在网格中,而不是以前的yapi中,我可以成功地筛选字符串。当然,我在两次实验中都有<meta charset="utf-8">。
因此,您应该验证不仅<meta charset="utf-8">存在于您的<head>页面中,而且数据也是以UTF-8编码的。在嵌入式数据的情况下(如我的实验),文件需要以UTF-8格式保存。
更新:评论中的讨论显示,主要问题是不区分大小写的过滤土耳其文本。
这个问题对我来说是全新的,但土耳其语有两个 i:一个在i上有点,另一个没有点ı。两个i都有相应的资本I:İ和I。所有的信息与许多其他语言并没有什么不同。主要问题是在选择Unicode表示的4个字符:土耳其字符i和I使用相同的代码,如拉丁语字符:U+0069和U+0049。只有字符ı和İ将映射到U+0131和U+0130 (参见这里)。这种映射使得不可能实现不区分大小写的比较或JavaScript函数、.toUpperCase()和.toLowerCase()。如果输入的文本包含拉丁字母i,那么函数.toUpperCase()应该将其转换为I,但对于土耳其语来说是错误的,而应该是İ。同样,.toLowerCase()应该为土耳其文本生成ı,为英文文本生成i。
因此,第一个重要信息是:如果没有输入语言的知识,就不可能实现一个通用版本的不区分大小写的比较。
好的。现在回到问题上来。如何在土耳其语篇中实现不区分大小写的搜索?在修改了4.7.1版jqGrid的许可协议后,我继续以免费jqGrid的名称开发免费版本(麻省理工学院和v2许可)。我在免费jqGrid的第一个版本中实现了许多新特性:Version4.8。维基文章中描述的“自定义过滤”功能可以帮助实现。
基于我创建的下面的演示特性。在实现过程中,我在免费jqGrid代码中做了一些小错误修复。因此,我在演示中使用了来自GitHub (http://rawgit.com/free-jqgrid/jqGrid/master/js/jquery.jqgrid.src.js)的最新源代码(请阅读关于URL的维基 )。
我在jqGrid中使用了以下选项
ignoreCase: false,
customSortOperations: {
teq: {
operand: "==",
text: "Turkish insensitive \"equal\"",
filter: function (options) {
var fieldData = String(options.item[options.cmName]).replace(/i/g,'İ').toUpperCase(),
searchValue = options.searchValue.replace(/i/g,'İ').toUpperCase();
return fieldData === searchValue;
}
},
tne: {
operand: "!=",
text: "Turkish insensitive \"not equal\"",
filter: function (options) {
var fieldData = String(options.item[options.cmName]).replace(/i/g,'İ').toUpperCase(),
searchValue = options.searchValue.replace(/i/g,'İ').toUpperCase();
return fieldData !== searchValue;
}
},
tbw: {
operand: "^",
text: "Turkish insensitive \"begins with\"",
filter: function (options) {
var fieldData = String(options.item[options.cmName]).replace(/i/g,'İ').toUpperCase(),
searchValue = options.searchValue.replace(/i/g,'İ').toUpperCase();
return fieldData.substr(0,searchValue.length) === searchValue;
}
},
tbn: {
operand: "!^",
text: "Turkish insensitive \"does not begin with\"",
filter: function (options) {
var fieldData = String(options.item[options.cmName]).replace(/i/g,'İ').toUpperCase(),
searchValue = options.searchValue.replace(/i/g,'İ').toUpperCase();
return fieldData.substr(0,searchValue.length) !== searchValue;
}
},
tew: {
operand: "|",
text: "Turkish insensitive \"end with\"",
filter: function (options) {
var fieldData = String(options.item[options.cmName]).replace(/i/g,'İ').toUpperCase(),
searchValue = options.searchValue.replace(/i/g,'İ').toUpperCase(),
searchLength = searchValue.length;
return fieldData.substr(fieldData.length-searchLength,searchLength) === searchValue;
}
},
ten: {
operand: "!@",
text: "Turkish insensitive \"does not end with\"",
filter: function (options) {
var fieldData = String(options.item[options.cmName]).replace(/i/g,'İ').toUpperCase(),
searchValue = options.searchValue.replace(/i/g,'İ').toUpperCase(),
searchLength = searchValue.length;
return fieldData.substr(fieldData.length-searchLength,searchLength) !== searchValue;
}
},
tcn: {
operand: "~",
text: "Turkish insensitive \"contains\"",
filter: function (options) {
var fieldData = String(options.item[options.cmName]).replace(/i/g,'İ').toUpperCase(),
searchValue = options.searchValue.replace(/i/g,'İ').toUpperCase();
return fieldData.indexOf(searchValue,0) >= 0;
}
},
tnc: {
operand: "!~",
text: "Turkish insensitive \"does not contain\"",
filter: function (options) {
var fieldData = String(options.item[options.cmName]).replace(/i/g,'İ').toUpperCase(),
searchValue = options.searchValue.replace(/i/g,'İ').toUpperCase();
return fieldData.indexOf(searchValue,0) < 0;
}
}
}选项customSortOperations为土耳其文本不区分大小写的比较定义了新的自定义操作。要使用该选项,只需为包含土耳其文本的列指定searchoptions中的操作:
searchoptions: { sopt: ["tcn", "tnc", "teq", "tne", "tbw", "tbn", "tew", "ten"] }因此,过滤使用"tcn“(Turkish insensitive "contains")作为默认筛选操作。如果使用searchOperators: true选项的filterToolbar,那么可以选择另一个搜索操作。我希望以上所有的自定义比较操作都是正确的,并且可以在土耳其网格中使用。
更新了2:我又找到了一个感兴趣的实现选项:支持参数的方法localeCompare。我在谷歌Chrome上测试过
"i".localeCompare("İ", "tr", { sensitivity: "base" }) === 0
"i".localeCompare("I", "tr", { sensitivity: "base" }) === 1
"ı".localeCompare("I", "tr", { sensitivity: "base" }) === 0
"ı".localeCompare("İ", "tr", { sensitivity: "base" }) === -1或
"i".localeCompare("İ", "tr", { sensitivity: "accent" }) === 0
"i".localeCompare("I", "tr", { sensitivity: "accent" }) === 1
"ı".localeCompare("I", "tr", { sensitivity: "accent" }) === 0
"ı".localeCompare("İ", "tr", { sensitivity: "accent" }) === -1但是在IE11中相同的测试失败了,与有关浏览器兼容性的信息相反。localeCompare的所有上述调用都在IE11中返回0。可以使用sensitivity的另一个值来获得预期的结果。相反,IE9为上述localeCompare调用返回1或-1。我认为它只考虑了第一个参数,并忽略了"tr", { sensitivity: "base" }部分。Chrome的结果看起来是这样的
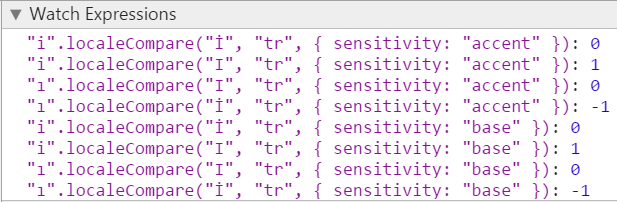
其中一个在Firefox中有相同的结果。
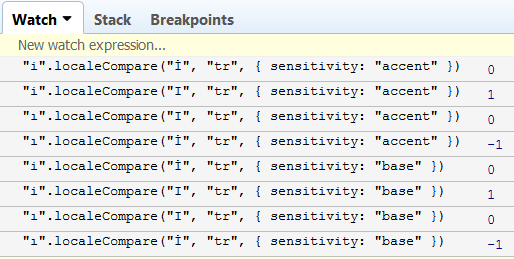
但不是在IE11

还有一种选择是使用ECMAScript国际化API类Intl.Collator (参见ecma-402和这里),如
new Intl.Collator("tr", { sensitivity: "base" }).compare("i", "İ")例如,IE在这种情况下似乎不太好。
无论如何,我认为可以通过包括浏览器检测部分来改进上述解决方案,浏览器检测部分选择闭包作为比较的实现,并在customSortOperations内部使用最好的实现。然而,上面的代码工作安全,但它可能不那么优雅。
https://stackoverflow.com/questions/29415506
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号