
从notepad++文件中提取每个引号之间的文本
从notepad++文件中提取每个引号之间的文本
提问于 2015-04-02 12:28:17
我的文件包含2000多个摘要,包含超过18000句,从标签开始,以标签结尾。我想通过使用notepad++查找信息,我的文件的视图如下:
<abstract>
<sentence>Activationofthe<conslex="CD28_surface_receptor"sem="G#protein_family_or_group"><conslex="CD28"sem="G#protein_molecule">CD28</cons>surfacereceptor</cons>providesamajorcostimulatorysignalfor<conslex="T_cell_activation"sem="G#other_name">Tcellactivation</cons>resultinginenhancedproductionof<conslex="interleukin-2"sem="G#protein_molecule">interleukin-2</cons>(<conslex="IL-2"sem="G#protein_molecule">IL-2</cons>)and<conslex="cell_proliferation"sem="G#other_name">cellproliferation</cons>.</sentence>
<sentence>In<conslex="primary_T_lymphocyte"sem="G#cell_type">primaryTlymphocytes</cons>weshowthat<conslex="CD28"sem="G#protein_molecule">CD28</cons>ligationleadstotherapidintracellularformationof<conslex="reactive_oxygen_intermediate"sem="G#inorganic">reactiveoxygenintermediates</cons>(<conslex="ROI"sem="G#inorganic">ROIs</cons>)whicharerequiredfor<conslex="CD28-mediated_activation"sem="G#other_name"><conslex="CD28"sem="G#protein_molecule">CD28</cons>-mediatedactivation</cons>ofthe<conslex="NF-kappa_B"sem="G#protein_molecule">NF-kappaB</cons>/<conslex="CD28-responsive_complex"sem="G#protein_complex"><conslex="CD28"sem="G#protein_molecule">CD28</cons>-responsivecomplex</cons>and<conslex="IL-2_expression"sem="G#other_name"><conslex="IL-2"sem="G#protein_molecule">IL-2</cons>expression</cons>.</sentence>
<sentence>Delineationofthe<conslex="CD28_signaling_cascade"sem="G#other_name"><conslex="CD28"sem="G#protein_molecule">CD28</cons>signalingcascade</cons>wasfoundtoinvolve<conslex="protein_tyrosine_kinase_activity"sem="G#other_name"><conslex="protein_tyrosine_kinase"sem="G#protein_family_or_group">proteintyrosinekinase</cons>activity</cons>,followedbytheactivationof<conslex="phospholipase_A2"sem="G#protein_molecule">phospholipaseA2</cons>and<conslex="5-lipoxygenase"sem="G#protein_molecule">5-lipoxygenase</cons>.</sentence>
<sentence>Ourdatasuggestthat<conslex="lipoxygenase_metabolite"sem="G#protein_family_or_group"><conslex="lipoxygenase"sem="G#protein_molecule">lipoxygenase</cons>metabolites</cons>activate<conslex="ROI_formation"sem="G#other_name"><conslex="ROI"sem="G#inorganic">ROI</cons>formation</cons>whichtheninduce<conslex="IL-2"sem="G#protein_molecule">IL-2</cons>expressionvia<conslex="NF-kappa_B_activation"sem="G#other_name"><conslex="NF-kappa_B"sem="G#protein_molecule">NF-kappaB</cons>activation</cons>.</sentence>
<sentence>Thesefindingsshouldbeusefulfor<conslex="therapeutic_strategies"sem="G#other_name">therapeuticstrategies</cons>andthedevelopmentof<conslex="immunosuppressants"sem="G#other_name">immunosuppressants</cons>targetingthe<conslex="CD28_costimulatory_pathway"sem="G#other_name"><conslex="CD28"sem="G#protein_molecule">CD28</cons>costimulatorypathway</cons>.</sentence>
</abstract>我想提取引号之间的文本,或者换句话说,要删除所有数据,除了整个文本中的双引号外,例如,我想要的输出如下
CD28_surface_receptor G#protein_family_or_group CD28 G#protein_molecule
primary_T_lymphocyte G#cell_type我使用.*"(.*)".*查找什么,然后用\1替换all。它只提取具有引号的文本,从每行的最后一行提取,但我想从所有doc和每一行中提取,因为我的文件中有更多具有双引号的字符串。
回答 1
Stack Overflow用户
发布于 2015-04-02 13:04:44
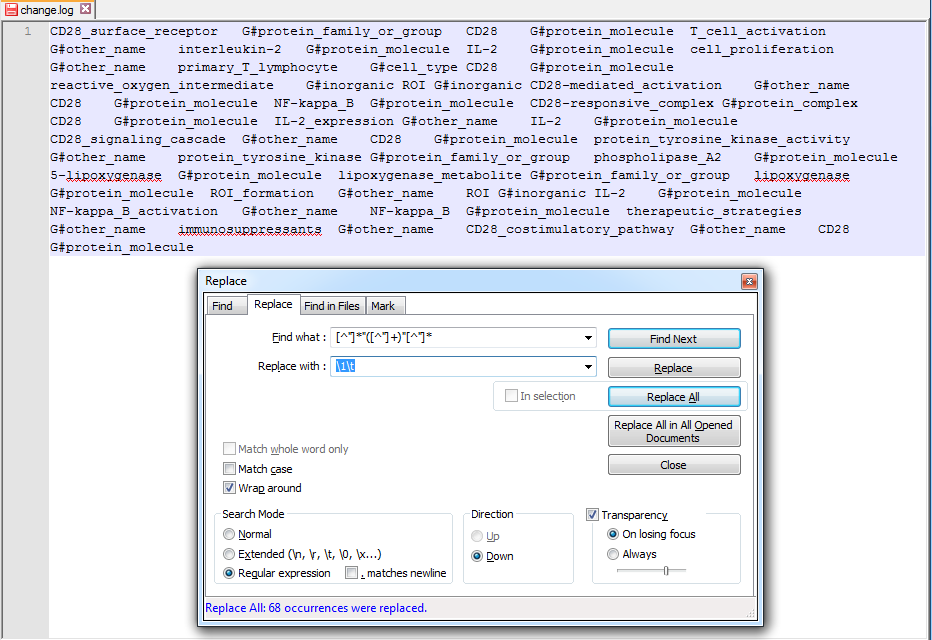
您可以使用[^"]*"([^"]+)"[^"]*查找什么,并用\1\r\n替换
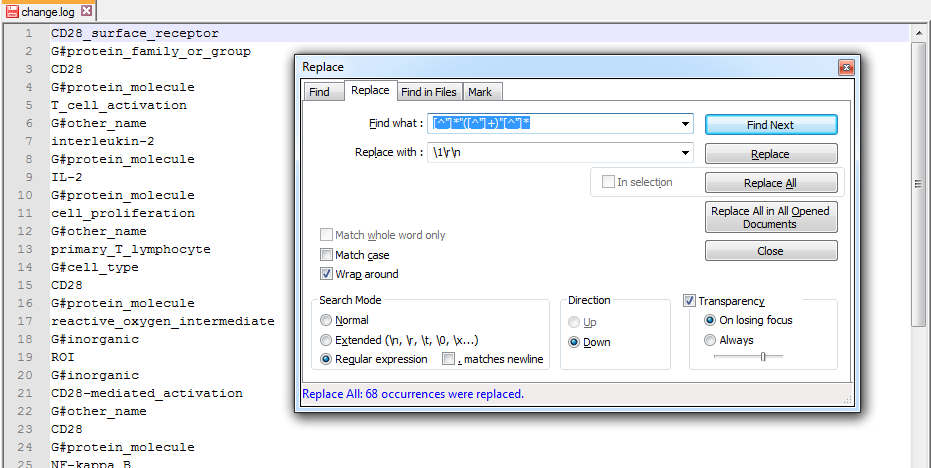
或者,要将它们分隔开,请用\1\t替换。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/29413002
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号