
使用Datafari从图像中搜索元数据
我正在寻找一个开放源码的文档管理系统,以索引所有类型的文件(文本: pdf,doc.,图片jpg,png,bmp.,视频mov,mp4.)我偶然发现了达塔法里
它使用Solr搜索引擎和ManifoldCF来管理内容存储库连接,并使用Tika连接器来帮助搜索元数据。
我安装了它,我正在尝试做这个设置,以便让它在元数据条件上搜索图像,但是到目前为止还没有结果。
我添加了一个带有一些元数据的映像的本地存储库:
<?xml version="1.0" encoding="UTF-8"?><html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="Artist" content="tarzan"/>
<meta name="date" content="2015-03-28T09:47:45"/>
<meta name="Print flags information" content="0 1 0 0 0 0 0 0 0 2"/>
<meta name="Slices" content="zebre (0,0,500,500) 1 Slices"/>
<meta name="ICC Untagged Profile" content="1"/>
<meta name="Compression Type" content="Baseline"/>
<meta name="subject" content="legs"/>
<meta name="subject" content="mammal"/>
<meta name="Image Description" content="this kind of animal is hard to see behind bar"/>
<meta name="Thumbnail Compression" content="JPEG (old-style)"/>
<meta name="Print flags" content="0 0 0 0 0 0 0 0 1"/>
<meta name="By-line" content="tarzan"/>
<meta name="Number of Components" content="3"/>
<meta name="Component 2" content="Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert"/>
<meta name="Component 1" content="Y component: Quantization table 0, Sampling factors 1 horiz/1 vert"/>
<meta name="tiff:ResolutionUnit" content="Inch"/>
<meta name="Object Name" content="king of disguise"/>
<meta name="Seed number" content="1"/>
<meta name="X Resolution" content="72 dots per inch"/>
<meta name="IPTC-NAA record" content="160 bytes binary data"/>
<meta name="Unknown tag (0x043a)" content="[239 bytes]"/>
<meta name="Version Info" content="1 (Adobe Photoshop, Adobe Photoshop CS6) 1"/>
<meta name="Component 3" content="Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert"/>
<meta name="dc:title" content="king of disguise"/>
<meta name="modified" content="2015-03-28T09:47:45"/>
<meta name="Thumbnail Data" content="JpegRGB, 160x160, Decomp 76800 bytes, 1572865 bpp, 6513 bytes"/>
<meta name="tiff:BitsPerSample" content="8"/>
<meta name="Application Record Version" content="42432"/>
<meta name="Resolution Info" content="72.0x72.0 DPI"/>
<meta name="meta:author" content="tarzan"/>
<meta name="meta:creation-date" content="2015-03-28T09:47:45"/>
<meta name="Caption digest" content="[16 bytes]"/>
<meta name="Creation-Date" content="2015-03-28T09:47:45"/>
<meta name="resourceName" content="zebre.jpg"/>
<meta name="Orientation" content="Top, left side (Horizontal / normal)"/>
<meta name="tiff:Orientation" content="1"/>
<meta name="tiff:Software" content="Adobe Photoshop CS6 (Windows)"/>
<meta name="Thumbnail Offset" content="354 bytes"/>
<meta name="Color Transform" content="YCbCr"/>
<meta name="Global Angle" content="120"/>
<meta name="Author" content="tarzan"/>
<meta name="Exif Image Height" content="500 pixels"/>
<meta name="Software" content="Adobe Photoshop CS6 (Windows)"/>
<meta name="tiff:YResolution" content="72.0"/>
<meta name="Y Resolution" content="72 dots per inch"/>
<meta name="dc:description" content="this kind of animal is hard to see behind bars"/>
<meta name="Color transfer functions" content="[112 bytes]"/>
<meta name="Keywords" content="legs"/>
<meta name="Keywords" content="mammal"/>
<meta name="Data Precision" content="8 bits"/>
<meta name="Coded Character Set" content="%G"/>
<meta name="dc:creator" content="tarzan"/>
<meta name="tiff:ImageLength" content="500"/>
<meta name="description" content="this kind of animal is hard to see behind bars"/>
<meta name="JPEG quality" content="12 (Maximum), Standard format, 3 scans"/>
<meta name="dcterms:created" content="2015-03-28T09:47:45"/>
<meta name="dcterms:modified" content="2015-03-28T09:47:45"/>
<meta name="Last-Modified" content="2015-03-28T09:47:45"/>
<meta name="Last-Save-Date" content="2015-03-28T09:47:45"/>
<meta name="Thumbnail Length" content="6513 bytes"/>
<meta name="Color Space" content="Undefined"/>
<meta name="Credit" content="tarzan"/>
<meta name="Global Altitude" content="30"/>
<meta name="meta:save-date" content="2015-03-28T09:47:45"/>
<meta name="Country/Primary Location Name" content="kenya"/>
<meta name="Content-Length" content="93123"/>
<meta name="Content-Type" content="image/jpeg"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.DefaultParser"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.jpeg.JpegParser"/>
<meta name="creator" content="tarzan"/>
<meta name="Color halftoning information" content="[72 bytes]"/>
<meta name="dc:subject" content="legs"/>
<meta name="dc:subject" content="mammal"/>
<meta name="tiff:XResolution" content="72.0"/>
<meta name="Date/Time" content="2015:03:28 09:47:45"/>
<meta name="Grid and guides information" content="[16 bytes]"/>
<meta name="Caption/Abstract" content="this kind of animal is hard to see behind bars"/>
<meta name="DCT Encode Version" content="1"/>
<meta name="Exif Image Width" content="500 pixels"/>
<meta name="Image Height" content="500 pixels"/>
<meta name="Pixel Aspect Ratio" content="1.0"/>
<meta name="Supplemental Category(s)" content="earthly creature"/>
<meta name="Image Width" content="500 pixels"/>
<meta name="Flags 0" content="64"/>
<meta name="Resolution Unit" content="Inch"/>
<meta name="Unknown tag (0x043b)" content="[557 bytes]"/>
<meta name="URL List" content="0"/>
<meta name="meta:keyword" content="legs"/>
<meta name="meta:keyword" content="mammal"/>
<meta name="Print Scale" content="Centered, Scale 1.0"/>
<meta name="tiff:ImageWidth" content="500"/>
<meta name="Flags 1" content="0"/>
<title>king of disguise</title>
</head>
<body/></html>在solr schema.xml中,我添加了所需的字段:
<fields>
...
<field name="subject" type="string" indexed="true" stored="true" multiValued="true" />然后我重新启动服务器。
在作业列表中的ManifoldCF管理中,我在作业中添加了一个Tika提取器转换:管道是: my存储库-> Tika extractor -> DatafariSolr
我尝试了Solr接口中的搜索:对于q,我在那里尝试了"subject:legs"和,我在Solr接口中检索了数据
但在Datafari搜索引擎里,我没有结果
对Datafari的帮助不是很有帮助,我查看了Manifoldcf文档,但是没有更多的运气。我希望有一个通过元数据进行这种搜索的实例。应该修改和/或测试什么来查看结果中的图像?
在Olivier之后更新答案:
谢谢你的帮助。这个工具确实很有希望,尽管我在配置它时仍然有问题:
我找不到datafari/WebContent/js/search.js。您的意思是:Datafari/tomcat/webapp/Datafari/js/search.js吗?
我补充了你的建议。
我还添加了“描述”和“创建者”字段。
1-在SolR搜索中:-如果我搜索Q“动物”,我可以检索我的图像(而不是用“动物”),这比“描述:动物”要好。-但如果我搜索“腿”,我什么也找不到.是因为有几个“主题”,有一种不同的方式搜索它吗?-如果我搜索“泰山”(从创建者领域),我也不会检索任何东西。
2-在Datafari搜索中:--我所做的更改似乎“破坏了”搜索:当我搜索时,车轮一直在转动。在控制台中,我有:
GET "http://localhost:8080/Datafari/css/menu.css" 404
L'utilisation d'XMLHttpRequest de façon synchrone sur le fil d'exécution principal est obsolète à cause de son impact négatif sur la navigation de l'utilisateur final.3-我为相同的字段添加了另一张带有其他元数据的图片,在SolR搜索中,如果我查询"jpg",它们都会出现(OK),但是在json响应中,其他字段不会出现在另一个图像上!
{
"responseHeader": {
"status": 0,
"QTime": 6,
"params": {
"indent": "true",
"q": "jpg\n",
"_": "1427968093838",
"wt": "json"
}
},
"response": {
"numFound": 2,
"start": 0,
"docs": [
{
"last_modified": "2015-03-28T09:47:45Z",
"id": "file:/home/olivier/Bureau/datafari/images/zebre.jpg",
"url": "file:/home/olivier/Bureau/datafari/images/zebre.jpg",
"source": "file",
"extension": "jpg",
"language": "en",
"content_en": [
""
],
"title_en": [
"zebre.jpg"
],
"title": [
"zebre.jpg"
],
"_version_": 1496971642075611100,
"allow_token_share": [
"__nosecurity__"
],
"deny_token_document": [
"__nosecurity__"
],
"deny_token_share": [
"__nosecurity__"
],
"allow_token_document": [
"__nosecurity__"
]
},
{
"last_modified": "2015-03-29T15:45:23Z",
"subject": [
"Description Mots clé"
],
"id": "file:/home/olivier/Bureau/datafari/metadata/image1toto.jpg",
"creator": [
"Description, IPTC - Auteur: beta"
],
"description": [
"Description Description : gamma"
],
"url": "file:/home/olivier/Bureau/datafari/metadata/image1toto.jpg",
"source": "file",
"extension": "jpg",
"language": "en",
"content_en": [
""
],
"title_en": [
"image1toto.jpg"
],
"title": [
"image1toto.jpg"
],
"_version_": 1497001790322770000,
"allow_token_share": [
"__nosecurity__"
],
"deny_token_document": [
"__nosecurity__"
],
"deny_token_share": [
"__nosecurity__"
],
"allow_token_document": [
"__nosecurity__"
]
}
]
},
"highlighting": {
"file:/home/olivier/Bureau/datafari/images/imagejpg.jpg": {
"content_fr": [
""
],
"content_en": [
""
]
},
"file:/home/olivier/Bureau/datafari/images/zebre.jpg": {
"content_fr": [
""
],
"content_en": [
""
]
},
"file:/home/olivier/Bureau/datafari/metadata/image1toto.jpg": {
"content_fr": [
""
],
"content_en": [
""
]
}
},
"spellcheck": {
"suggestions": []
},
"capsuleSearchComponent": {}
}我很困惑。
奥利维尔·塔沃德回答后的编辑
很抱歉我的回答太晚了,我正在忙一些紧急的自动取款机,不能按我的意愿进行测试/回答。
我遵循了您的步骤(非常有教益,谢谢),并设法在客户端搜索中得到了结果:)
但是:
1-我不得不用通配符在datafari gui中找到它:“一匹伪装的马”,=>,我不得不写上‘**马*’,而不是‘马’。
2-如何检索多个字段的数据(例如:meta:关键字.)
<meta name="meta:keyword" content="legs"/>
<meta name="meta:keyword" content="mammal"/>3-我有一个“标准”安装,但我有一个404的本地主机:8080/Datafari/css/menu.css,也许这就是为什么我得到搜索轮,直到我刷新页面
回答 2
Stack Overflow用户
发布于 2015-04-07 11:29:06
好的,我会试着完成答案。
我从一个普通的Datafari安装开始,我在datafari.com上下载了这些步骤。
假设我们希望在Solr中添加一个新的元数据字段,名为meta:author (源中的作者),在Datafari中添加名为authorname的元数据字段。
让我们看看将字段显示到Datafari UI中的每一步,并允许使用Solr搜索字段。
1)编辑solrconfig.xml
我们希望将源文件:meta:author的原始元数据映射到一个名为authorname的新Solr字段。因此,我们必须编辑Solr单元请求处理程序:
<requestHandler name="/update/extract"
startup="lazy"
class="solr.extraction.ExtractingRequestHandler" >
<lst name="defaults">
<str name="scan">false</str>
<str name="captureAttr">true</str>
<str name="lowernames">true</str>
<str name="fmap.language">ignored_</str>
<str name="fmap.meta_author">authorname</str>
<str name="fmap.source">ignored_</str>
<str name="uprefix">ignored_</str>
<str name="update.chain">datafari</str>
<bool name="ignoreTikaException">true</bool>正确的语法是meta_author (而不是meta:author),因为行
<str name="lowernames">true</str>
文档说:"lowernames=true|false -用下划线将所有字段名映射到小写“
您还可以在配置中看到,我们在忽略的动态字段中存储所有被忽略的元数据。我请您更改schema.xml中字段的配置,并将stored=false更改为store=true,以查看Tika找到的所有元数据(并查看将字段映射到Solr的正确语法),例如:
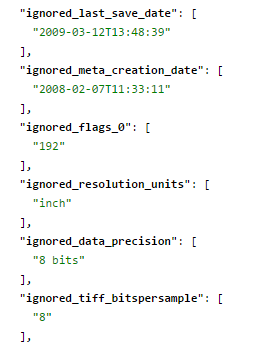
2)编辑schema.xml
现在,我们希望将新字段添加到Solr架构中。因此,添加以下一行:
<field name="authorname" type="text_en" indexed="true" stored="true" multiValued="true"/>好的,到目前为止,我们可以启动指数化的ManifoldCF和新的领域是很好地存在于Solr。
3)将新字段添加到搜索编辑solrconfig.xml中,在select请求处理程序中添加该字段:
<str name="qf">author title_en^50 title_fr^50 content_fr^10 content_en^10 source^20 extension^20
</str>在内核重新加载之后,我们现在可以搜索并找到新字段的数据。
4)将Datafari UI配置为Datafari/tomcat/webapp/Datafari/js/main.js(源代码)或Datafari/tomcat/webapp/Datafari/js/main.js(已安装版本),更改行:
Manager.store.addByValue("fl", 'title,url,id,extension'); 并添加要添加的字段,此处为autorname
Manager.store.addByValue("fl", 'title,url,id,extension, authorname');最后一步是更改Javascript文件search.js : datafari/WebContent/js/search.js (源代码)或Datafari/tomcat/webapp/Datafari\js/search.js(已安装版本),添加您要添加的代码: doc.subject。例如,如果您想在文档的URL之后添加它:(我在前面的回答中犯了一个错误,现在它是正确的)
elm.find('.doc:last .address').append('<span>' + AjaxFranceLabs.tinyUrl(decodeURIComponent(url)) + '</span>')
elm.find('.doc:last .address').append('<div id="author">' + doc.author );最后,对于每个文档末尾的字段作者,Datafari Ui应该是这样的:
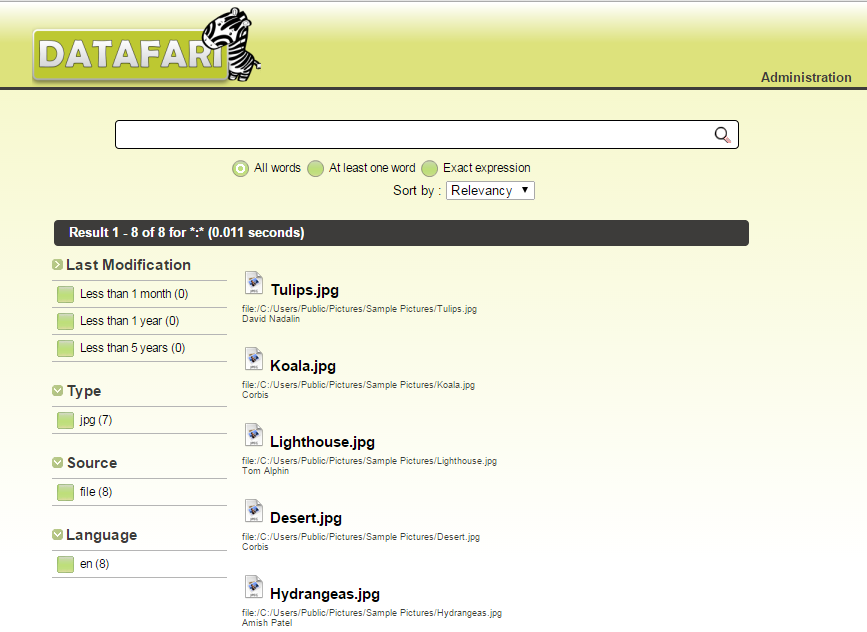
如果你还有什么问题告诉我。
诚挚的问候
编辑在user29296之后的另一个问题
- 关于通配符,它取决于您使用的字段类型和您需要的搜索类型。通常,您不必在单词之前添加额外的通配符。如果您想要搜索任何具有提供后缀的前缀,则需要一个ReversedWildcardFilterFactory。
- 检索多个字段的数据--在这种情况下,我不理解您的问题是什么。能给我举个例子吗?如果更改搜索处理程序选择配置,则可以在qf部分中添加要搜索的字段。因此,只需在这里添加meta_keyword字段。因此,客户端在执行搜索时也会搜索该字段。
- Menu.css 404错误此错误对应用程序没有任何影响。此缺失文件的修复将包含在Datafari的下一次更新中。
Stack Overflow用户
发布于 2015-03-31 20:15:46
谢谢你使用Datafari。要将字段的显示添加到UI中,必须修改2个文件:
- Datafari/tomcat/webapp/Datafari/js/main.js 更改行文: Manager.store.addByValue("fl",'title,url,id,扩展名‘); 并在示例subject中添加要添加的字段: Manager.store.addByValue("fl",'title,url,id,扩展名,subject');
- datafari/WebContent/js/search.js
添加要添加代码:
doc.subject的字段的显示。例如,如果您想在文档的URL之后添加它: elm.find('.doc:last .address').append(doc.subject);
如果您的问题与搜索有关:搜索datafari/solr/solr_home/FileShare/conf/solrconfig.xml:腿不检索任何结果,则必须更改中的Solr配置
<requestHandler name="/select" class="solr.SearchHandler">并将字段subject in qf (如果需要,则添加pf )到列表中:
<str name="qf">subject title_en^50 title_fr^50 content_fr^10 content_en^10 source^20 extension^20
</str>如果您感兴趣,我们开始使用这里有一些文件。
https://stackoverflow.com/questions/29327874
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号