
LR(0)解析器不是也使用查找头吗?
LL(1)-parser需要一个前瞻性符号来决定使用哪种产品。这就是为什么我总是认为“展望”这个词是使用的,当解析器查看下一个输入令牌而不“消费”它(也就是说,它仍然可以在下一个操作中从输入中读取)。然而,LR(0)解析器使我怀疑这是否正确:
我看到的LR(0)-parsers的每个例子都使用下一个输入令牌来决定是移位还是减少。在减少的情况下,不消耗输入令牌。
我使用免费软件工具"ParsingEmu“生成LR表,并在下面对单词"aab”执行LR评估。如您所见,列头包含标记。从计算中可以看到,解析器通过查看下一个输入令牌来决定使用哪一列。但是,当解析器在步骤4-6中减少时,输入不会改变(尽管解析器在执行到下一个状态的转换时需要知道下一个输入令牌"$“)。
语法:
S -> A
A -> aA
A -> b表:
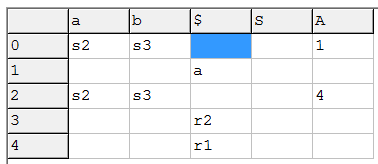
评价:
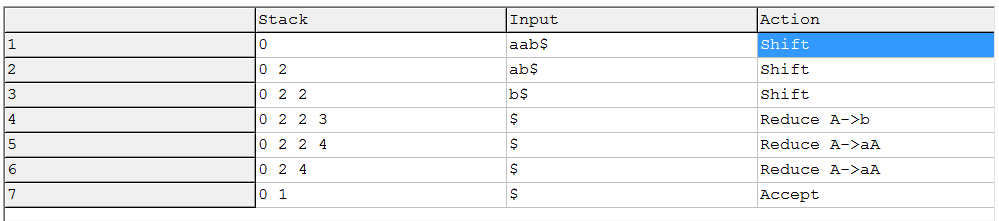
现在,由于我的困惑,我做了以下假设:
- 我对“展望”的定义(展望=未被消耗的输入令牌)的假设是错误的。对于LL-解析器或LR-解析器,“向前看”只意味着两种不同的事情。如果是这样,那又如何定义“前瞻性”呢?
- LR-解析器(从理论上讲,当您使用下推自动机时)有额外的内部状态,它们通过将输入令牌放在堆栈上来消耗输入令牌,因此只需查看堆栈就可以做出移位减少决策。
- 上面所示的评价是LR(1)。如果是这样的话,LR(0)的计算结果会是什么样子?
现在,什么是正确的,1,2或3或完全不同的东西?
回答 1
Stack Overflow用户
发布于 2015-03-14 18:52:11
准确地说,这一点很重要:
LR(k)解析器使用当前解析器状态和k个前瞻性符号来决定是否减少产生,如果是,则决定生产。
它还使用一个shift转换表来决定在移动下一个输入令牌之后应该移动到哪个解析状态。不管k的值如何,shift转换表都是由当前状态和正在移动的(单个)令牌键决定的。
如果在给定的解析器状态下,可能同时产生shift和reduce操作,那么解析器就会有shift/reduce冲突,并且它是无效的。因此,从理论上讲,上述两种判定都是不确定的。
如果在给定的解析器状态下,不可能进行约简,并且下一个输入符号不能移动(也就是说,该状态与该输入符号没有转换),则解析失败,算法终止。
另一方面,如果移位转换导致指定的接受状态,则解析成功,算法终止。
所有这一切意味着,前瞻性是用来预测哪一个,如果有的话,应该减少。在LR(0)解析器中,必须在读取下一个输入令牌之前决定转换(更准确地说,是尝试移位),但是要转换到do的状态的计算是在读取令牌之后进行的,此时如果不可能发生移位,则会发出错误信号。
LL(k)解析器必须预测哪种产品一看到非终端就用非终端代替非终端。基本LL算法从包含$的堆栈开始,并在完成之前执行以下任何一项操作:
- 如果堆栈的顶部是非终端,则将堆栈的顶部替换为该非终端的一个结果,使用下一个k输入符号来决定哪个输入符号(不移动输入光标),然后继续。
- 如果堆栈的顶部是终端,则读取下一个输入令牌。如果是同一终端,则弹出堆栈并继续。否则,解析失败,算法完成。
- 如果堆栈为空,则解析成功,算法完成。(我们假设输入末尾有唯一的EOF标记$。)
在这两种情况下,查找都有相同的含义:它包括在不移动输入光标的情况下查看输入标记。
如果k为0,那么:
- LR(k)解析器必须在不检查输入的情况下决定是否减少,这意味着没有任何状态可以有两个不同的约简动作或一个约简和移位动作。
- LL(k)解析器必须在不检查输入的情况下决定哪个非终端的产生是可实现的。实际上,这意味着每个非终端只能有一个产品,这意味着语言必须是有限的。
https://stackoverflow.com/questions/29049554
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号