
在Python NaN中重新将NaN响应更改为零的风险
在Python NaN中重新将NaN响应更改为零的风险
提问于 2015-03-06 06:46:25
我有一个大型的调查数据集来清理(300列,30000行),而且这些列是混合的。我用Python来对付熊猫和小矮人。我非常喜欢使用Python在学习车轮阶段。
- 有些列对问题有Y或N个答案(这些问题被填上"Y“或"N")。
- 一些是likert量表的问题,有5个可能的答案。在CSV文件中,每个答案(同意、不同意等)有自己的专栏。这已经导入为1作为一个是和NaN,否则。
- 其他问题有多达10个可能的答案(例如年龄),这些问题在一栏中作为字符串输入,即"a. 0-18“或"b. 19-25”等等。改变这些会很有趣的!
当我通过时,我将Y/N的答案改为1或0。然而,对于likert刻度栏,我担心做同样的事情可能会有风险。是否有人认为,目前是否最好将这些数据保留为NaN?性别是一样的--有一个单独的列用于男性和一个女性,两者都填充1表示是和NaN代表no。
我打算使用Python来进行数据分析/图表(将导入matplotlib & seaborn)。由于这对我来说是新的,我猜想我现在所做的改变以后可能会产生意想不到的后果!
如果你能提供任何指导,我将不胜感激。
提前谢谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-03-06 07:39:51
如果没有0,那意味着什么,用一个值(为了方便起见)填充NA是很好的。这完全取决于你的数据。也就是说,300x30k并不是那么大。将其保存为CSV,并在IPython笔记本中进行实验,Pandas可能会在一秒钟内读取它,所以如果你搞砸了什么,就重新加载。
下面是一段快速代码,它可以将任何多列问题集压缩为具有一定数量的单个列:
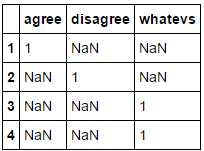
df = pd.DataFrame({
1: {'agree': 1},
2: {'disagree': 1},
3: {'whatevs': 1},
4: {'whatevs': 1}}).transpose()
df
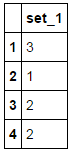
question_sets = {
'set_1': ['disagree', 'whatevs', 'agree'], # define these lists from 1 to whatever
}
for setname, setcols in question_sets.items():
# plug the NaNs with 0
df[setcols].fillna(0)
# scale each column with 0 or 1 in the question set with an ascending value
for val, col in enumerate(setcols, start=1):
df[col] *= val
# create new column by summing all the question set columns
df[setname] = df[question_set_columns].sum(axis=1)
# delete all the old columns
df.drop(setcols, inplace=True, axis=1)
df
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/28893592
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号