
Oracle查询根据下一条记录的值来计数行
向查询输入值:数据库中的1-20值: 4,5,15,16
我想要一个查询,它给出结果如下
Value - Count
===== - =====
1 - 3
6 - 9
17 - 3基本上,首先生成从1到20的连续数,计数可用的数字。我编写了一个查询,但无法让它完全工作:
with avail_ip as (
SELECT (0) + LEVEL AS val
FROM DUAL
CONNECT BY LEVEL < 20),
grouped_tab as (
select val,lead(val,1,0) over (order by val) next_val
from avail_ip u
where not exists (
select 'x' from (select 4 val from dual) b
where b.val=u.val) )
select
val,next_val-val difference,
count(*) over (partition by next_val-val) avail_count
from grouped_tab
order by 1它给了我计数,但我不知道如何将行压缩为三行。
我无法添加完整的查询,我一直得到“提交时出错”。出于某种原因,它不喜欢联合条款。因此,我将查询作为图像附加:(
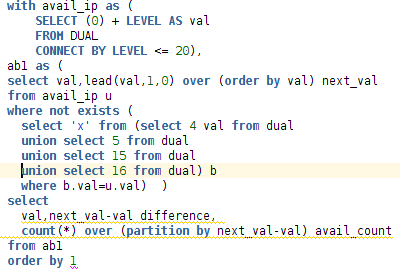
关于具体要求的更多细节:
我正在编写一个ip管理模块,我需要在一个ip块中找到可用的(免费) ip地址。块可以是/16或/24,甚至是/12。为了使其更具挑战性,我也支持IPv6,这样就可以管理更多的数字。所有已发出的ip地址都以十进制格式存储。所以我的想法是首先生成从网络地址到广播地址的块范围内的所有ip小数。就像。在/24中,地址为255个,/16为64K。
现在,第二,查找块内所有已使用的地址,并找出可用的地址数与启动ip。所以在上面的例子中,启动一个ip- 3地址是可用的,从6,9开始是可用的。
我最后要担心的是,查询应该能够运行得足够快,可以运行数百万个数字。
如果我原来的问题不够清楚的话,我再次表示歉意。
回答 1
Stack Overflow用户
发布于 2015-02-24 19:14:21
类似于你尝试过的想法:
with all_values as (
select :start_val + level - 1 as val
from dual
connect by level <= (:end_val - :start_val) + 1
),
missing_values as (
select val
from all_values
where not exists (select null from t42 where id = val)
),
chains as (
select val,
val - (row_number() over (order by val) + :start_val - 1) as chain
from missing_values
)
select min(val), count(*) - 1 as gap_count
from chains
group by chain
order by min(val);如果start_val为1,end_val为20,表t42中的数据为:
MIN(VAL) GAP_COUNT
---------- ----------
1 3
6 9
17 4 不过,我已经将end_val包括在内;不确定您希望它是包容性的还是排他性的。我也许已经让你需要的更灵活--你的版本也假设你总是从1开始。
all_values CTE与您的基本相同,生成起始值和结束值之间的所有数字-1到20 (包括!)在这种情况下。
missing_values CTE将移除表中的值,因此留给1,2,3,6,7,8,9,10,11,12,13,14,17,18,19,20。
chains的CTE完成了神奇的部分。这将得到每个值之间的差异,以及您期望它在连续列表中的位置。这个区别--我称之为“链”--对于所有连续的缺失值都是一样的;1, 2,3都得到0,6到14都得到2,17到20都得到4。然后这个链值可以用来分组,你可以使用聚合计数和分钟来得到你需要的答案。
简化版本的SQL,专门用于1-20,显示每个中间步骤的数据。这将适用于任何上限,只需更改20,但假设您总是从1开始。
https://stackoverflow.com/questions/28704027
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号