
在图像中查找已知文本(引导OCR)
我在寻找一种在图像中定位已知文本的方法。
具体来说,我正在创建一个工具,将一组扫描页面转换为支持搜索和copy+paste的PDF。我理解这通常是如何做到的: OCR页面,保留文本的位置,然后将文本作为不可见层添加到PDF中。Acrobat具有此功能,tesseract可以输出hOCR文件(包含识别的文本及其位置),hocr2pdf可以使用这些文件生成文本层。
不幸的是,我的源图像质量相当低(最多150 DPI,有大量JPEG伪影,以及一些文本背后的非实心背景),导致了相当差的OCR结果。但是,我确实有一个文本的副本(无照片和布局),出现在每一页。
将已经知道的文本与扫描页面上的位置匹配起来似乎要容易得多,但我没有发现任何具有这种内置功能的软件。我如何利用现有的软件来做到这一点?
编辑:文字的大小和字体各不相同,尽管段落是一致的。
回答 1
Stack Overflow用户
发布于 2015-02-25 11:32:48
我突然想到的想法将是相互关联的。所以,我会把你知道发生在页面上的单词列表,一次一个地渲染到画布上,创建一个单词的图片。您将需要使用类似的字体和大小与文档中的单词--这是我在评论中要求的。然后,我会运行一个标准化的互相关字的图片与扫描的图像,看看它发生在哪里。我会用ImageMagick完成所有这些工作,这是Windows和OSX (在OSX上使用homebrew )提供的,并且包含在大多数Linux发行版中。
因此,让我们对你的问题的第二段进行屏幕抓取,并寻找单词pretty -在这里您提到了相当差的OCR。
首先,您需要将单词pretty呈现在白色背景上。命令将如下所示:
convert -background white -fill black -font Times -pointsize 14 label:pretty word.png结果:
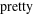
然后使用Fred来自这里的脚本执行标准化的互相关,如下所示:
normcrosscorr -p word.png scan.png correlation-result.png
Match Coords: (504,30) And Score In Range 0 to 1: (0.999803)你可以看到匹配的坐标是504,30。
结果:

另一个想法
另一个想法可能是使用谷歌的Tesseract-OCR,并将标准字典替换为包含您正在处理的页面上的单词的文本文件。
https://stackoverflow.com/questions/28684747
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号