
如何在字形排序中找到它的项目?
上周,一个问题定义了n乘m矩阵上的zag排序,并问了how to list the elements in that order。
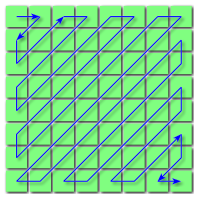
我的问题是如何快速找到在字形排序中的第一项?也就是说,在不遍历矩阵的情况下(对于大的n和m,太慢了)。
例如,在图片中使用n=m=8和(x,y)描述(行、列)
f(0) = (0, 0)
f(1) = (0, 1)
f(2) = (1, 0)
f(3) = (2, 0)
f(4) = (1, 1)
...
f(63) = (7, 7)具体问题:百亿(1e10)项在百万矩阵的Z字形排序中是什么?
回答 2
Stack Overflow用户
发布于 2015-02-11 16:18:58
- 让我们假设所需的元素位于矩阵的上半部分。对角线的长度是
1, 2, 3 ..., n。 - 让我们找出所需的对角线。它满足以下属性:
sum(1, 2 ..., k) >= pos但sum(1, 2, ..., k - 1) < pos。1, 2, ..., k之和为k * (k + 1) / 2。所以我们只需要找到最小的整数k,比如k * (k + 1) / 2 >= pos。我们要么使用二进制搜索,要么显式地解决这个二次不等式。 - 当我们知道
k时,我们只需要找到这个对角线的pos - (k - 1) * k / 2元素。我们知道它从哪里开始,我们应该在哪里移动(上下移动,取决于k的奇偶性),因此我们可以使用一个简单的公式找到所需的单元格。
该解决方案具有O(1)或O(log n)时间复杂度(这取决于我们是使用二进制搜索还是在步骤2中显式地求解不等式)。
如果所需的元素位于矩阵的下半部,我们可以为pos' = n * n - pos + 1解决这个问题,然后利用对称性得到原问题的解。
我在这个解决方案中使用了基于1的索引,使用基于0的索引可能需要在某个地方添加+1或-1,但是解决方案的思想是相同的。
如果矩阵是矩形的,而不是方形的,我们需要考虑对角线的长度是这样的:1, 2, 3, ..., m, m, m, .., m, m - 1, ..., 1(如果是m <= n),当我们搜索k时,如果k <= m和k * (k + 1) / 2 + m * (k - m)的话,那么和就变成了k * (k + 1) / 2。
Stack Overflow用户
发布于 2015-02-17 20:08:05
import math, random
def naive(n, m, ord, swap = False):
dx = 1
dy = -1
if swap:
dx, dy = dy, dx
cur = [0, 0]
for i in range(ord):
cur[0] += dy
cur[1] += dx
if cur[0] < 0 or cur[1] < 0 or cur[0] >= n or cur[1] >= m:
dx, dy = dy, dx
if cur[0] >= n:
cur[0] = n - 1
cur[1] += 2
if cur[1] >= m:
cur[1] = m - 1
cur[0] += 2
if cur[0] < 0: cur[0] = 0
if cur[1] < 0: cur[1] = 0
return cur
def fast(n, m, ord, swap = False):
if n < m:
x, y = fast(m, n, ord, not swap)
return [y, x]
alt = n * m - ord - 1
if alt < ord:
x, y = fast(n, m, alt, swap if (n + m) % 2 == 0 else not swap)
return [n - x - 1, m - y - 1]
if ord < (m * (m + 1) / 2):
diag = int((-1 + math.sqrt(1 + 8 * ord)) / 2)
parity = (diag + (0 if swap else 1)) % 2
within = ord - (diag * (diag + 1) / 2)
if parity: return [diag - within, within]
else: return [within, diag - within]
else:
ord -= (m * (m + 1) / 2)
diag = int(ord / m)
within = ord - diag * m
diag += m
parity = (diag + (0 if swap else 1)) % 2
if not parity:
within = m - within - 1
return [diag - within, within]
if __name__ == "__main__":
for i in range(1000):
n = random.randint(3, 100)
m = random.randint(3, 100)
ord = random.randint(0, n * m - 1)
swap = random.randint(0, 99) < 50
na = naive(n, m, ord, swap)
fa = fast(n, m, ord, swap)
assert na == fa, "(%d, %d, %d, %s) ==> (%s), (%s)" % (n, m, ord, swap, na, fa)
print fast(1000000, 1000000, 9999999999, False)
print fast(1000000, 1000000, 10000000000, False)所以第100亿个元素(序数9999999999的元素)和100亿-第一个元素(序数10^10的元素)是:
[20331, 121089]
[20330, 121090]https://stackoverflow.com/questions/28458756
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号