
理解感知器
我刚开始上机器学习课,我们复习了感知器。对于家庭作业,我们应该:“选择合适的二维(平面)训练和测试数据集,使用10个数据点进行训练,5个数据点进行测试。”然后我们应该编写一个程序,它将使用感知器算法并输出:
- 关于训练数据点是否线性可分的评论
- 关于测试点是否为线性可分点的评论
- 您最初选择的权重和常数
- 最终解方程(决策边界)
- 算法所做的权重更新总数。
- 在培训集上进行的迭代总数。
- 对训练数据和测试数据的最终错误分类错误(如果有的话)。
我已经读了好几遍我的书的第一章,我仍然有困难,充分理解知觉。
我知道如果一个点被错误分类,你会改变权重,直到不再有错误分类,我想我很难理解的是
- 我使用测试数据的目的是什么,这与培训数据有什么关系?
- 我怎么知道某一观点是否被错误分类了?
- 如何选择测试点、训练点、阈值或偏倚?
如果没有我的书提供好的例子,我真的很难知道如何弥补其中的一个。如你所知,我很迷茫,任何帮助都是非常感谢的。
回答 2
Stack Overflow用户
发布于 2015-02-01 13:45:15
我使用测试数据的目的是什么,这与培训数据有什么关系?
想一想一台感知器还是个小孩子。你想教一个孩子如何区分苹果和橘子。你向它展示5个不同的苹果(全是红色/黄色)和5个橘子(形状不同),同时告诉它在每一次转弯时都能看到什么(“这是一只苹果,这是一个橘子)。假设孩子有完美的记忆力,如果你给他举足够的例子,他就会学会理解苹果是什么,桔子是什么。他最终会在没有你告诉他的情况下,就开始使用meta-features (类似形状)。这就是Perceptron所做的。当你给他看了所有的例子之后,你会从一开始,这就是一个新的纪元。”
当你想测试孩子的知识时会发生什么?你给它看一些新的,。一个绿色的苹果(不仅仅是黄色/红色),一个葡萄柚,也许是一个西瓜。为什么不向孩子展示与训练前完全相同的数据呢?因为这个孩子记忆力很好,它只会告诉你你对他说的话。您将看不到如何将从已知的数据推广到未见的数据,除非您有不同的培训数据,这是您在培训期间从未向他展示过的。如果孩子在测试数据上表现糟糕,而在训练数据上却有100%的表现,你就会知道他没有学到任何东西--这只是重复他在训练中被告知的话--你训练他太久了,他只记住了你的例子,而不知道苹果是什么,因为你给了他太多的细节--这就是overfitting.。仅防止您的感知器(!)识别训练数据,你必须在一个合理的时间停止训练,并在训练和测试集的大小之间找到一个很好的平衡。
我怎么知道某一观点是否被错误分类了?
如果它和它应该是不同的。假设苹果有0级,橙色有1级(在这里,您应该开始阅读单个/多层感知器以及多个感知器的神经网络是如何工作的)。网络将接受您的输入。它的编码方式与此无关,假设输入是一个字符串"apple“。然后你的训练集是{(apple3,0 1,0),(apple3,0 2,0),(apple3,0 3,0),(orange2,1 1,1),(orange2,1 2,1).}。由于您事先知道这个类,网络将输出输入"apple1“的1或0。如果它输出1,则执行(targetValue-actualValue) = (1-0) =1.1在本例中意味着网络提供了错误的输出。将其与增量规则进行比较,您将了解到这个小等式是更大的更新方程的一部分。如果你得到一个1,你将执行一个重量更新。如果目标值和实际值相同,您将始终得到0,并且您知道网络没有错误分类。
如何选择测试点、训练点、阈值或偏倚?
实际上,偏见和阈值本身并不是“选择”的。偏差像任何其他单元一样,使用简单的“技巧”,即使用偏差作为值为1的附加输入单元--这意味着实际的偏差值被编码在这个附加单元的权重中,我们使用的算法将确保它自动地为我们学习偏差。
根据激活函数的不同,阈值是预先确定的。对于一个简单的感知器,分类如下:
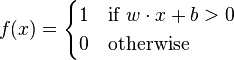
由于我们使用的是二进制输出(介于0到1之间),所以将阈值设置为0.5是一个很好的开始,因为这正好是0,1范围的中间。
关于选择训练和测试点的最后一个问题:这是相当困难的,你是通过经验来做到的。在这里,首先要实现简单的逻辑函数,如AND、OR、XOR等。您将所有内容放入您的培训集中,并使用与培训集相同的值进行测试(因为对于XOR、y等,只有4种可能的输入- 00、10、01、11)。对于复杂的数据,如图像,音频等,你将不得不尝试和调整你的数据和功能,直到你觉得网络可以与它的良好工作,你想要它。
Stack Overflow用户
发布于 2015-01-31 21:00:56
我使用测试数据的目的是什么,这与培训数据有什么关系?
通常,为了评估某一特定算法的性能,首先对其进行训练,然后使用不同的数据来测试它在以前从未见过的数据上的表现。
我怎么知道某一观点是否被错误分类了?
您的培训数据有标签,这意味着对于培训集中的每一个点,您都知道它属于哪一类。
如何选择测试点、训练点、阈值或偏倚?
对于简单的问题,你通常把所有的训练数据分成80/20左右。你在80%的训练中进行训练,然后用剩下的20%进行测试。
https://stackoverflow.com/questions/28256441
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号