
C++文本文件不会保存在Unicode中,它一直保存在ANSI中。
基本上,我需要能够用Unicode创建一个文本文件,但是无论我做什么,它都会保存在ANSI中。
这是我的密码:
wchar_t name[] = L"中國哲學書電子化計劃";
FILE * pFile;
pFile = fopen("chineseLetters.txt", "w");
fwrite(name, sizeof(wchar_t), sizeof(name), pFile);
fclose(pFile);这是我的“chineseLetters.txt”的输出:
-NWòTx[øfû–P[SŠƒR õ2123另外,应用程序在MBCS中,不能被更改为Unicode,因为它需要同时使用Unicode和ANSI。
我真的很想在这里提供一些帮助。谢谢。
谢谢你这么快的回复!它起作用了!
简单地添加L"\uFFFE中國哲學書電子化計劃“仍然不起作用,文本编辑器仍然将其识别为CP1252,因此我执行了2次fwrite,而不是1次,一次用于BOM,另一次用于字符,下面是我的代码:
wchar_t name[] = L"中國哲學書電子化計劃";
unsigned char bom[] = { 0xFF, 0xFE };
FILE * pFile;
pFile = fopen("chineseLetters.txt", "w");
fwrite(bom, sizeof(unsigned char), sizeof(bom), pFile);
fwrite(name, sizeof(wchar_t), wcslen(name), pFile);
fclose(pFile);回答 2
Stack Overflow用户
发布于 2015-01-20 23:38:20
我需要能够用Unicode创建一个文本文件。
Unicode不是编码,您的意思是UTF-16 do吗?这是用于内存中内部字符串存储的两字节编码单元(编码Windowsx86/x64),一些Windows应用程序(如记事本)在UI中错误地将UTF-16LE描述为“Unicode”。
fwrite(名称、大小(Wchar_t)、sizeof(name)、pFile);
您已经将字符串的内存存储直接复制到文件中。如果您在Windows/MSVCRT下编译它,那么由于内部存储编码是UTF-16 as,您生成的文件被编码为UTF-16 as。如果在其他环境中编译这一点,则会得到不同的结果。
这是我的“chineseLetters.txt”的输出:-NWòTx[Šƒ-P]SŠƒR 2123
如果您将文件误解为Windows代码页1252 (西欧),那么UTF-16LE编码的数据就是这样的。
如果您已经将该文件加载到诸如记事本之类的Windows应用程序中,它可能不知道该文件包含UTF-16 in编码的数据,因此默认使用默认的特定于地区的(ANSI,mbcs)代码页作为编码,从而生成上述莫吉贝克。
当你制作一个UTF-16文件时,你应该在它的开头放置一个字节顺序标记字符U+FEFF,让消费者知道它是UTF-16 let还是UTF-16‘s。这也为像记事本这样的应用程序提供了一个提示,即该文件完全包含UTF-16,而不是ANSI。因此,您可能会发现,编写L"\uFEFF中國哲學書電子化計劃"将使输出文件在记事本中显示得更好。
但是,最好将wchar_t转换为char字节,并以明确声明的特定编码方式(例如UTF-8),而不是依赖于C库碰巧使用的内存存储格式。在Win32上,您可以使用API接口,或者使用Mr.C64描述的大范围开放的ccs来实现这一点。如果您选择用ccs编写UTF-16 in文件,它将为您提供BOM。
Stack Overflow用户
发布于 2015-01-20 22:42:47
" Unicode“是一个通用术语,您可能需要澄清您计划在文件中使用哪种Unicode编码。
Unicode UTF-8是一种常见的选择(它特别适合在不同平台之间交换文本数据,因为它没有"endiannes“的概念,与UTF-16不同,它没有小的端点/大端的混淆,而且它在互联网上得到了广泛的使用),但也有其他的选项(例如,Windows上的UTF-16,它直接映射到wchar_t-strings中的视觉C++)。
如果您使用的是Visual ccs,您可以在fopen() (或_wfopen())的第二个参数中指定一个fopen()属性,选择需要的编码,例如用于UTF-8编码的"ccs=UTF-8"。
您可以在fopen()上阅读更多有关这方面的详细信息,例如:
fopen支持Unicode文件流。若要打开Unicode文件,请向fopen,传递指定所需编码的ccs标志,如下所示。fp = fopen("newfile.txt","rt+,ccs=编码"); 允许编码的值是UNICODE,UTF-8,和UTF-16LE.。
我认为,对于UNICODE,它们指的是UTF-16 the (即大端UTF-16);另外两个选项是很清楚的。
编辑
我尝试使用这段代码,它可以很好地使用Unicode UTF-8保存中文文本(我使用了Visual 2013):
wchar_t name[] = L"中國哲學書電子化計劃";
FILE * file = fopen("C:\\TEMP\\ChineseLetters.txt", "wt, ccs=UTF-8");
...check for error...
fwrite(name, sizeof(wchar_t), _countof(name)-1, file);
fclose(file);注意,在将中文文本粘贴到源文件并保存之后,Visual编辑器发现它需要保存Unicode中的源文件以避免文本信息松散,并显示了一个要求确认的对话框。
因此,考虑将源文件保存在Unicode中,如果其中包含一些“硬编码”Unicode文本(在生产质量的/C++代码中,您可能希望将文本保存在资源文件中)。
还请注意,我在_countof()调用中使用了sizeof()而不是sizeof()。
你有:
fwrite(名称、大小(Wchar_t)、大小(名称)、文件);
但这是错误的,因为您希望将的计数指定为第三个参数,而不是以字节为单位的总大小(注意,在MSVC中,sizeof(wchar_t) == 2,即wchar_t是两个chars,即两个字节**)。
此外,您必须将-1考虑到wchar_t的总缓冲区长度,因为您不希望在Unicode字符串缓冲区中写入NUL-terminating wchar_t。
(对于具有未知静态大小的Unicode UTF-16 wchar_t字符串,只需使用wcslen()获取wchar_ts的计数(不包括终止NUL) )。
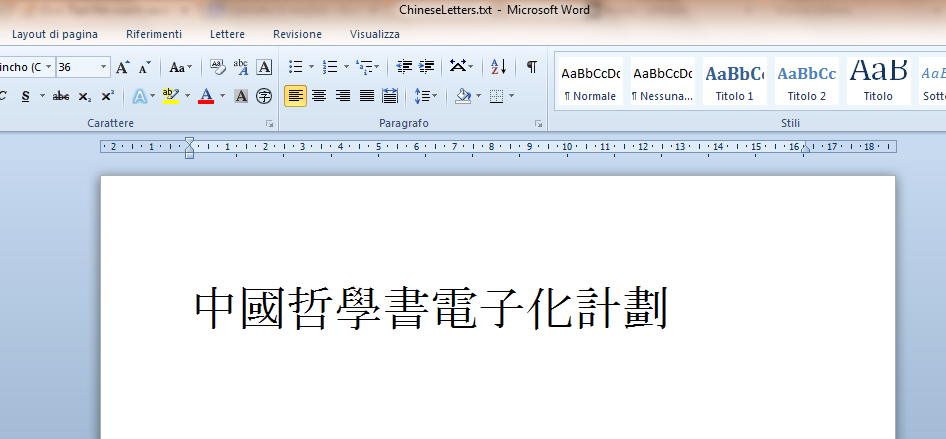
以上所写的UTF-8文件就是这样正确地以Word打开的:
https://stackoverflow.com/questions/28055802
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号