
最接近的职位匹配
我有已知职称的主列表,并寻找从搜索的术语中提取相同的方法。例如:
搜索职位:高级数字营销专家
摘录至:高级数字营销
搜索职务:零售商店销售助理;全职
摘录到:零售销售助理
因此,我试图提取有助于清理所搜索的查询的参数。
1)数据库中两个令牌的出现。(要对这些术语相互关联的程度进行数学评估),例如:
t01->t0 or t1 Senior || java--->226374
t02->t0 or t2 Senior || software--->2566450
t03->t0 or t3 Senior || engineer--->7220787
t12->t1 or t2 java || software--->315397
t13->t1 or t3 java || engineer--->407682
t23->t2 or t3 software || engineer--->11533495
total =t01+t02+t03+t12+t13+t23
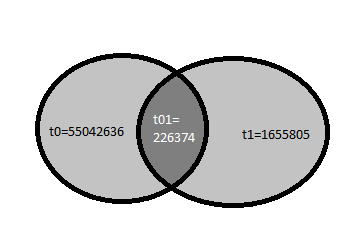
2)令牌在整个db中的出现时间为1。示例:
t0-> Senior----->55042636
t1-> java----->1655805
t2-> software----->26136204
t3-> engineer----->815749123)取相关令牌之和,将最小阈值设置为5%,得到以下输出,即(txy*100)/total >5
我的输出:高级软件工程师
有谁有过类似的项目或进一步改进的想法吗?
回答 1
Stack Overflow用户
发布于 2015-01-20 09:19:06
确定查询和列表条目之间的相似性的一种标准方法是向量空间模型。粗略地说,您可以通过以下步骤来构建这样一个模型:
- 定义向量空间(脱机)的维数
term-list = []
for-all job titles in your master list:
for-all words in the current job-title:
canonicalize(current-word) // e.g. to-lower-case, etc.
if not contains(term-list, current-word):
add(current-word, term-list)
sort(term-list)
n = size(term-list)n的长度term-list是向量空间的大小。
- 将主列表中的每个职务名称与向量(脱机)关联
vector-list = []
vector = []
fill(vector, 0, n-1, 0) // initialize to n zeros
for-all job titles in your master list:
for-all words in the current job-title:
canonicalize(current-word) // e.g. to-lower-case, etc.
term-index = index-of(current-word, term-list)
vector[term-index]++
normalize(vector) // scale vector to length = 1
add(vector, vector-list)- 将每个搜索
query转换为向量以及(联机)
这与2下面的代码完全一样,只不过您只有一个for-循环(内部循环),在其中迭代查询中的单词,而不是主列表职务名称中的单词。而且,出于明显的原因,您不需要vector-list。
结果是一个规范化的query-vector。
- 用余弦相似度法(
query-vector(在线))度量给定职位的相关性
similarities-vector = []
for-all job-title vectors in vector-list:
similarity = dotProduct(query-vector, job-title-vector)
add(similarity, similarities-vector)结果是查询与存储在similarities-vector中的主列表的每个条目之间的相似值。
这是一个非常普遍的模型,其吸引力在于它的简单性。然而,对于手头的工作来说,这是否是一个非常好的模式,这是一个值得商榷的问题,因为你的职位通常只包含一小部分单词,而这些词可能在每个职位中只出现一次。但你可以试试。
https://stackoverflow.com/questions/28041012
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号