
将绘图导出到Plot.ly时出错
我有以下数据(前20行的样本):
- 编码变量值
- 1 Z1周刊0 0
- 2 Z2周刊0 0
- 3 Z3周刊0 0
- 4 Z4周刊0 0
- 5 Z5周刊0 0
- 6 Z6周刊0 0
- 7 Z7周刊0 0
- 8 Z8周刊0 0
- 9 Z9周刊0 0
- 10 Z101周刊0 NA
- 11 Z102周刊0 NA
- 12 Z1周刊1 0
- 13 Z2周刊1 0
- 14 Z3周刊1 0
- 15 Z4周刊1 0
- 16 Z5周刊1 0
- 17 Z6周刊1 0
- 18 Z7周刊1 0
- 19 Z8周刊1 0
我用这样的方法画出来:
pZ <- ggplot(zmeltdata,aes(x=variable,y=value,color=Codering,group=Codering)) +
geom_line()+
geom_point()+
theme_few()+
theme(legend.position="right")+
scale_color_hue(name = "Treatment group:")+
scale_y_continuous(labels = percent)+
ylab("Germination percentage")+
xlab("Week number")+
labs(title = "Z. monophyllum germination data")
pZ图表显示得很好:
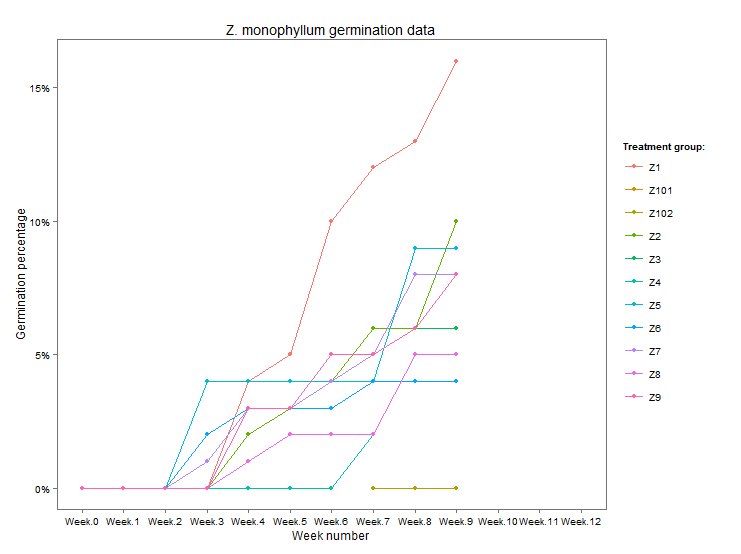
然而,当我想将它导出到Plot.ly时,我会得到以下错误:
> py <- plotly()
> response<-py$ggplotly(pZ)
Error in if (all(xcomp) && all(ycomp)) { :
missing value where TRUE/FALSE needed
In addition: Warning message:
In trace.list[[lind[1]]]$y == trace.list[[lind[2]]]$y :
longer object length is not a multiple of shorter object length我已经寻找了这些错误,但是解释彻底地让我困惑。“需要真假值的缺失值。”如果您在您的过程中使用逻辑术语( if / all /TRUE/FALSE等),则应该会发生这种情况,而我根本没有!即使在我得到的图的值中检查任何NA时:
> is.na(pZ)
data layers scales mapping theme coordinates facet plot_env labels
FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE 当有不同长度的对象时,“更长的对象长度不是短对象长度的倍数”应该会弹出,但是我只使用一个具有3行完全相同长度的对象。当我请求这些行时,图的值确实给了我一个NULL,但这应该会发生..
> nrow(zmeltdata)
[1] 143
> nrow(test)
NULL总之,我很困惑,不知道如何正确处理这些错误,有人能详细说明一下吗?
耽误您时间,实在对不起。
编辑:我尝试用1:100的随机样本将一个不同的图形导出到Plot.ly,这很好,我很确定错误在我的数据中,我只是想不出如何修复它。
EDIT2:回复@Gregor:
> dput(head(zmeltdata, 20))
structure(list(Codering = structure(c(16L, 19L, 20L, 21L, 22L,
23L, 24L, 25L, 26L, 17L, 18L, 16L, 19L, 20L, 21L, 22L, 23L, 24L,
25L, 26L), .Label = c("B1", "C2", "C3", "C8", "M1", "M101", "M102",
"M2", "M3", "M4", "M5", "M6", "M7", "M8", "M9", "Z1", "Z101",
"Z102", "Z2", "Z3", "Z4", "Z5", "Z6", "Z7", "Z8", "Z9"), class = "factor"),
variable = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), .Label = c("Week.0",
"Week.1", "Week.2", "Week.3", "Week.4", "Week.5", "Week.6",
"Week.7", "Week.8", "Week.9", "Week.10", "Week.11", "Week.12"
), class = "factor"), value = c(0, 0, 0, 0, 0, 0, 0, 0, 0,
NA, NA, 0, 0, 0, 0, 0, 0, 0, 0, 0)), .Names = c("Codering",
"variable", "value"), row.names = c(NA, 20L), class = "data.frame")而尾巴:
> dput(tail(zmeltdata, 43))
structure(list(Codering = structure(c(19L, 20L, 21L, 22L, 23L,
24L, 25L, 26L, 17L, 18L, 16L, 19L, 20L, 21L, 22L, 23L, 24L, 25L,
26L, 17L, 18L, 16L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 17L,
18L, 16L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 17L, 18L), .Label = c("B1",
"C2", "C3", "C8", "M1", "M101", "M102", "M2", "M3", "M4", "M5",
"M6", "M7", "M8", "M9", "Z1", "Z101", "Z102", "Z2", "Z3", "Z4",
"Z5", "Z6", "Z7", "Z8", "Z9"), class = "factor"), variable = structure(c(10L,
10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 11L, 11L, 11L, 11L,
11L, 11L, 11L, 11L, 11L, 11L, 11L, 12L, 12L, 12L, 12L, 12L, 12L,
12L, 12L, 12L, 12L, 12L, 13L, 13L, 13L, 13L, 13L, 13L, 13L, 13L,
13L, 13L, 13L), .Label = c("Week.0", "Week.1", "Week.2", "Week.3",
"Week.4", "Week.5", "Week.6", "Week.7", "Week.8", "Week.9", "Week.10",
"Week.11", "Week.12"), class = "factor"), value = c(0.1, 0.06,
0.05, 0.09, 0.04, 0.08, 0.05, 0.08, 0, 0, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA)), .Names = c("Codering",
"variable", "value"), row.names = 101:143, class = "data.frame")我一点也不惊讶,在数据集中有相当多的NA,但它们不应该被证明是一个问题,因为我以前使用过类似的(更大的)数据集。
如果您愿意的话,我还有.csv文件供您使用:https://www.mediafire.com/?jij1vlp14a29ntt
回答 1
Stack Overflow用户
发布于 2015-01-09 16:50:26
问题是如何处理娜的..。我通过运行以下代码获得了https://plot.ly/~marianne2/417/z-monophyllum-germination-data/:
pZ <- ggplot(na.omit(zmeltdata), aes(x=variable, y=value, color=Codering,
group=Codering)) +
geom_line() +
geom_point() +
# theme_few() +
theme(legend.position="right") +
scale_color_hue(name="Treatment group:") +
# scale_y_continuous(labels = percent) +
ylab("Germination percentage") +
xlab("Week number") +
labs(title="Z. monophyllum germination data")
py$ggplotly(pZ, kwargs=list(fileopt="overwrite", filename="test_zdata"))请注意,我必须注释掉theme_few()和scale_y_continuous(labels = percent),因为只加载"ggplot2",就会得到以下错误:
Error: could not find function "theme_few"和
Error in structure(list(call = match.call(), aesthetics = aesthetics, :
object 'percent' not found分别使用。我想这些都是依赖问题(也许您使用的是一个版本的“version”?)。
我不知道theme_few()的魔力是什么,但如果我不在zmeltdata上使用na.omit(),我的pZ情节如下所示:
哦,“每周10”后面是“每周1”,而不是“每周9”之后。所以无论如何你都不想把这个发出去!所以我不能准确地复制你的ggplot例子。但我想知道你是否真的想保留这些NA( CSV本身读"NA",我以为是空白的“单元格”)。你难道不想事先处理这些吗?
注意,当我在na.omit()上不使用zmeltdata时,我会收到以下警告消息
Warning messages:
1: Removed 20 rows containing missing values (geom_path).
2: Removed 47 rows containing missing values (geom_point).再说一遍,除了纯粹的显示/绘图考虑之外,因为这看起来像科学数据,你不想用实际数字来表示周数吗?如果你真的想要字符串的话,你不想用数字来填充数字吗?(“每周01”、“每周02”等)看起来丢失的数据都在跟踪..。只有几周的10+还没有数据,对吗?
谢谢你的报道,
玛丽安
https://stackoverflow.com/questions/27861827
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号