
如何充分利用集群中的所有火花节点?
我已经启动了一个10节点集群与EC2-脚本在独立模式的火花。我从s3 shell中访问PySpark存储桶中的数据,但是当我在PySpark上执行转换时,只使用一个节点。例如,下面将读取来自CommonCorpus的数据:
bucket = ("s3n://@aws-publicdatasets/common-crawl/crawl-data/CC-MAIN-2014-23/"
"/segments/1404776400583.60/warc/CC-MAIN-20140707234000-00000-ip-10"
"-180-212-248.ec2.internal.warc.gz")
data = sc.textFile(bucket)
data.count()当我运行这个程序时,我的10个奴隶中只有一个处理数据。我知道这一点,因为当从Spark控制台查看时,只有一个从(213)有任何活动日志。当我在Ganglia中查看该活动时,这个节点(213)是在运行该活动时唯一一个在mem使用中出现尖峰的从节点。
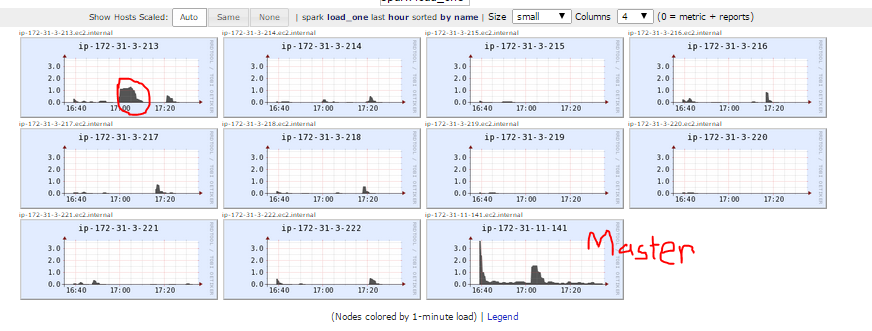
此外,当我只使用一个从站的ec2集群运行相同的脚本时,性能完全相同。我正在使用星火1.1.0和任何帮助或建议,我们非常感谢。
回答 1
Stack Overflow用户
发布于 2014-12-24 04:58:20
...ec2.internal.warc.gz
我认为您遇到了一个相当典型的问题,因为压缩文件不能并行加载。更具体地说,一个gzipped文件不能由多个任务并行加载,所以Spark将用1个任务加载它,从而为您提供一个包含1个分区的RDD。
(但是,请注意,Spark可以并行加载10个压缩文件;只是这10个文件中的每一个只能由1个任务加载。您仍然可以获得跨文件的并行性,只是不能在文件中实现。)
通过显式检查RDD中的分区数,您可以确认只有一个分区:
data.getNumPartitions()可以在RDD上并行运行的任务数量的上限是RDD中的分区数或集群中的从核数,以较低的.为准。
在您的例子中,这是RDD分区的数量。您可以通过重新划分RDD来增加这一点,如下所示:
data = sc.textFile(bucket).repartition(sc.defaultParallelism * 3)为什么sc.defaultParallelism * 3
星火调优指南建议使用2-3 tasks per core,而sc.defaultParalellism给出了集群中的核数。
https://stackoverflow.com/questions/27531816
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号