
朴素贝叶斯评级
假设我有一个具有以下数据的培训集:
Type | Size | Price | Rating | SUGGESTION
---------------------------------------------------
Shirt M Budget 0 Bad
Trouser L Budget 4.2 Good
Shirt M Expensive 2.3 Good
....etc....这里以SUGGESTION为类,我们需要在提供输入样例时提出这个类。也就是说,当给定一个输入样本(与训练数据集不同)时,我们需要确定它是Good还是Bad。
能够理解基于互联网上的一个例子的概率计算:
数据集:
输入样本的计算:

我的数据集中的疑问是,我有一个名为Rating的列。那么,对于这一列,我们也像其他列一样进行概率计算(就像上面的截图中那样)?或者我们需要考虑另一种方法来处理某一列的值?比如说均值和标准差?
谢谢
回答 2
Stack Overflow用户
发布于 2014-12-06 16:20:58
列“大小”和“价格”表示分类数据(实际上,序号,但这是另外一点)。虽然你也可以将“评级”建模为“分类值”,但这可能是个坏主意,最好将数据建模为数字。这就是为什么。
数据作为分类数据和数字数据的区别在于不同的值。假设你对x有三个观察:x=12,x=13,x=1344。那么问题是:P(x=12)、P(x=1344)和P(x=13)的概率有多大不同?答案在很大程度上取决于这些值所代表的数据类型。
例如,它x表示用户id或什么排序是无关的,这些概率可能是任意的。但是如果x表示的是,比如说,工资率,那么与第三个数值相比,12和13之间显然没有太大的差别。
它还可以帮助你推断出更多关于你的数据的知识。例如,dataset中可能没有4.9值,但是有很多4.8和5.0。然后,您的模型在这两者之间进行“内插”,给出4.9的概率,即使数据集中没有显示它。
因此,是的,您应该使用数值分布(例如,高斯分布)对您的评级数据。我还建议进行一些清理:显然,0代表“未评分”,而不是“非常糟糕”,因此您可能需要告诉您的模型(例如,用平均评分替换0)。
Stack Overflow用户
发布于 2014-12-06 16:57:11
如何处理评级栏的答案是通常的答案:这取决于。
首先,我要确定评级的数字到底代表什么。我希望评分是整数值,就像为电影评论分配一些明星一样。在这种情况下,十进制值表明评级是另一回事。检查测试数据应该会告诉您这些值是否已经是离散值,或者它们是否是沿着数字线任何地方都可能下降的数字。例如,如果唯一的值是0、1.1、2.3、3.5、4.2和5.6,那么处理它们就像S、M和L一样。
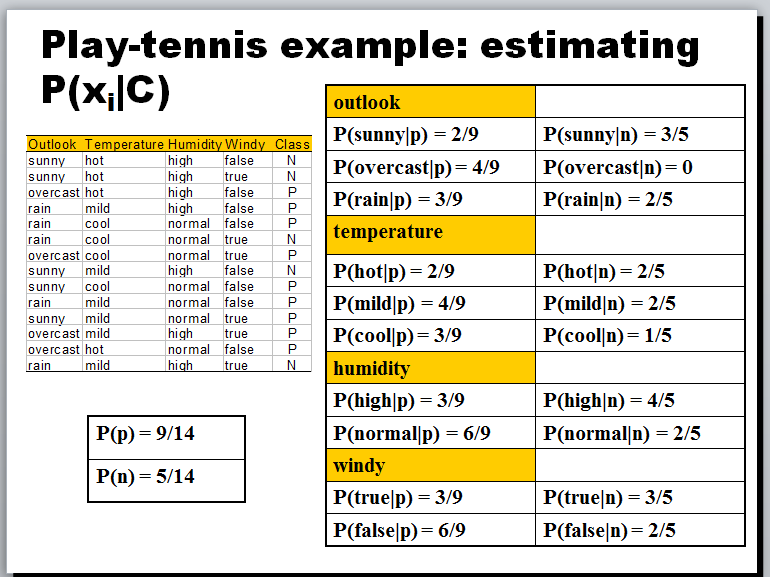
例如,如果评级值是数字的,并且下降在0到10之间,你能处理它们类似于网球例子中的温度吗?温度可以被测量为一个数值,但已经映射成热、冷等组。
如果分组不起作用,它们可能需要进行一些数学计算,并根据数据的分布计算概率。
最后,您可以尝试另一种算法,如K最近邻算法。
https://stackoverflow.com/questions/27331678
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号