
在Matlab中用独立RAM读取大文本文件
在Matlab中用独立RAM读取大文本文件
提问于 2014-11-21 16:26:01
我想读取一个大约2GB的大文本文件,并对该数据执行一系列操作。以下方法
tic
fid=fopen(strcat(Name,'.dat'));
C=textscan(fid, '%d%d%f%f%f%d');
fclose(fid);
%Extract cell values
y=C{1}(1:Subsampling:end)/Subsampling;
x=C{2}(1:Subsampling:end)/Subsampling;
%...
Reflectanse=C{6}(1:Subsampling:end);
Overlap=round(Overlap/Subsampling);在我的内存使用中出现一个奇怪的峰值时,在读取C (C=textscan(fid, '%d%d%f%f%f%d');)后立即失败:
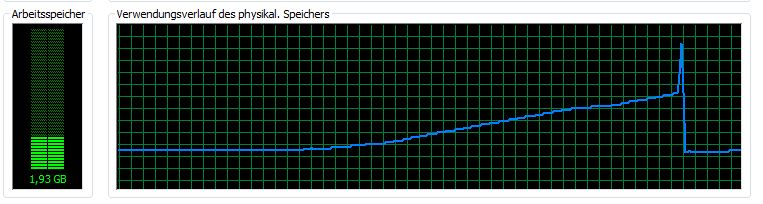
导入这样大小的文件的最佳方法是什么?是否有一种方法可以使用textscan()读取文本文件的各个部分,或者是否有其他更适合此任务的函数?
编辑:文本扫描中的每一列都包含3D点的信息字段信息:
width hieght X Y Z Grayscale
345 453 3.422 53.435 0.234 200
346 453 3.545 52.345 0.239 200
... % and so on for ~40 millon points回答 1
Stack Overflow用户
回答已采纳
发布于 2014-11-24 22:55:48
如果您可以单独处理每一行,那么下面的代码将允许您这样做。如果您想指定一个数据块,我已经包括了start_line和end_line。
headerSpec = '%s %s %s %s %s %s';
dataSpec = '%f %f %f %f %f %f';
fid=fopen('data.dat');
% Read Header
names = textscan(fid, headerSpec, 1, 'delimiter', '\t');
k = 0;
% specify a start and end line for getting a block of data
start_line = 2;
end_line = 3;
while ~feof(fid)
k=k+1;
if k < start_line
continue;
end
if k > end_line
break;
end
% get data
C = textscan(fid, dataSpec, 1, 'delimiter', '\t');
row = [C{1:6}]; % convert data from cell to vector
% do what you want with the row
end
fclose(fid);有可能读取整个文件,但这将取决于您有多少内存可用,如果matlab有任何限制。这可以通过在命令窗口键入memory来看到。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/27065926
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号