
在一个多层面的识别关系中,是否应该在其大孩子中建立一个大父钥匙,一个主钥匙?
几天前我问过这个这里,但是还没有得到太多的视图,更不用说回复了,所以我重新发布到堆栈溢出。
我正在为一个会议票务系统建模一个DB。在此系统中,与会者是属于会议的与会者组的成员。这些关系是识别的,因此FKs必须是各自子女中的PKs。
我现在的模式:
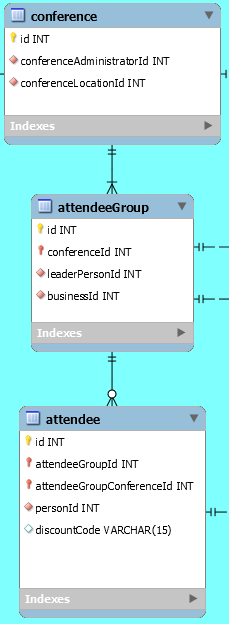
Q:在attendee表中使用attendeeGroupConferenceId FK (作为PK )是否合适,就像MySQL工作台自动为我设置的那样?
一方面,一个人会得到一个性能提升,保持它在那里快速联系在“入住”。但是,这并不是绝对必要的,因为id、attendeeGroupId以及相应的attendeeGroup表中的conferenceId的相应查找已经足够了。(因此成为冗余数据。)
对我来说,这似乎违反了某种形式的正常化,但我计划保持它的速度提升,如所述。我只是好奇如何正确的设计,关于给予它PK状态或不。
回答 1
Stack Overflow用户
发布于 2014-11-22 09:31:43
您肯定不需要attendeeGroupConferenceId表中的attendee。这是多余的,并且注意到候选密钥是(attendeeGroupId, personId)的组合,而不是attendeeGroupConferenceId单独的组合。表attendee似乎也违背了第二范式(2NF)本身。
我的建议是删除属性attendeeGroupConferenceId。在任何情况下,您都可以加入查询中的表来获取额外的信息,而不是保留额外的属性。
https://stackoverflow.com/questions/27050070
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号